
The growth in AI workloads over the past two years has pushed GPU demand into a new orbit. Enterprises that once used a handful of A100s now require entire racks of Hopper-class accelerators to train, tune, and serve models efficiently. With the introduction of the NVIDIA H200, organizations are re-evaluating their cluster designs, comparing it directly to the widely adopted NVIDIA H100.
Let’s analyze the architectural differences, workload behaviors, cluster scaling considerations, and enterprise implications of choosing between the H200 and H100. In this article, we aim to help technical leaders make informed decisions as AI infrastructure requirements evolve.
Why are businesses comparing the NVIDIA H200 and H100?
Three industry shifts make this comparison especially relevant:
1. Model sizes have accelerated past earlier hardware assumptions
Modern LLMs increasingly exceed 70 billion parameters. Enterprises deploying AI assistants, generative pipelines, or multi-agent systems need GPUs that can store and serve these models efficiently.
2. Inference is becoming the dominant operational workload
Across many enterprise AI environments, inference and fine-tuning workloads now outweigh full-scale model training. This places memory, batch efficiency, and model capacity at the center of GPU decisions.
3. Private cloud and dedicated GPU infrastructure are surging
With hyperscaler costs climbing and predictable pricing becoming a priority, organizations are turning to single-tenant private cloud deployments. Choosing the right GPU matters for cost control, compliance, and long-term scalability.
What are the architectural differences between the NVIDIA H200 and H100?
Both GPUs use NVIDIA’s Hopper architecture and support next-generation AI workloads, but the H200 introduces a major upgrade: HBM3e memory with significantly higher capacity and bandwidth.
Here’s the full comparison:
| Feature | NVIDIA H200 | NVIDIA H100 |
| Architecture | Hopper | Hopper |
| Memory Type | HBM3e | HBM3 |
| Memory Capacity | 141 GB | 80 GB |
| Memory Bandwidth | Up to ~4.8 TB/s | 3.35 TB/s |
| FP64 | 34 TFLOPS | 34 TFLOPS |
| FP64 Tensor Core | 67 TFLOPS | 67 TFLOPS |
| FP32 | 67 TFLOPS | 67 TFLOPS |
| TF32 Tensor Core | 989 TFLOPS | 989 TFLOPS |
| FP16 / BF16 Tensor Core | High-capacity FP16 compute | 1979 TFLOPS |
| FP8 Tensor Core | Supported (HBM3e optimized) | 3958 TFLOPS |
| NVLink | Next-gen NVLink supported | 900 GB/s |
| MIG Support | Yes | Up to 7 MIGs |
| Confidential Computing | Yes | Yes |
| Best For | Large-model inference, RAG, long-context LLMs | Training, HPC compute, tensor-core scaling |
The difference in memory capacity (141 GB vs 80 GB) is the most important architectural divergence and shapes nearly all workload recommendations.
How does the H200’s HBM3e memory affect performance?
HBM3e is the core reason the H200 behaves differently from the H100.
The H200’s memory advantages include:
- Accommodating much larger models on a single GPU
- Reducing or eliminating tensor parallelism for many workloads
- Enabling larger batch sizes for inference
- Improving throughput for long-context transformers
- Minimizing memory spillover into CPU RAM
- Lowering latency for interactive applications
For enterprises deploying production LLMs, the H200’s memory capacity is often the deciding factor.
Which GPU is better for AI training: the H200 or H100?
For most training scenarios, the H100 remains the stronger choice, especially in multi-GPU environments.
Based on the NVIDIA H100 datasheet:
- H100 delivers up to 4X faster GPT-3 175B training than A100
- H100 provides 60 TFLOPS of FP64 tensor compute, a major advantage for HPC
- H100’s NVLink bandwidth (900 GB/s) enables highly efficient multi-GPU scaling
These capabilities make the H100 ideal for:
- Foundational model training
- Multi-node training using tensor or pipeline parallelism
- HPC workloads requiring FP64 precision
- Dense scientific compute
The H200 can assist memory-bound training, but its primary value is not raw tensor compute throughput.
Which GPU is better for LLM inference?
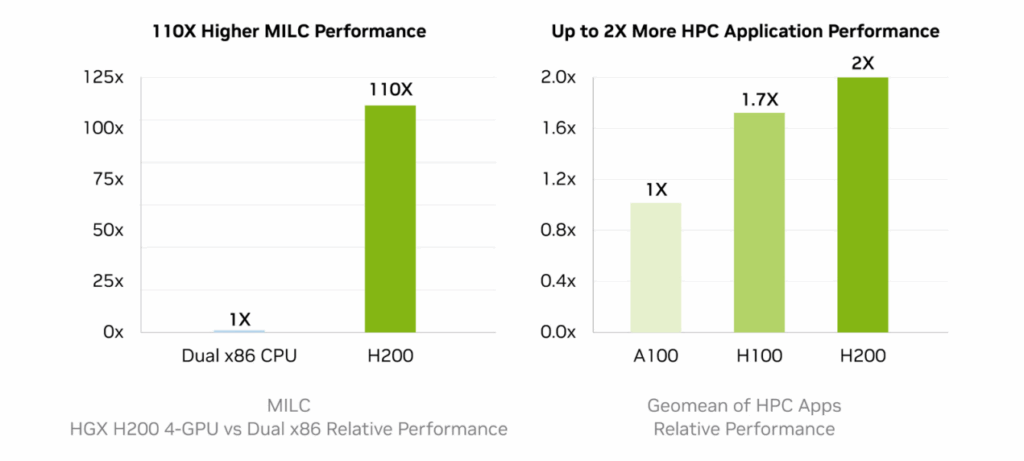
The H200 is the stronger GPU for large-model inference due to its memory capacity and higher HBM bandwidth.
H200 inference advantages
- Hosts very large LLMs directly on GPU memory
- Allows larger batch sizes with lower latency
- Reduces cross-GPU communication
- Supports long-context models with less fragmentation
- Simplifies production deployment architecture
Where the H100 still performs well
- Smaller or mid-size models
- Inference on 30B–70B models when paired with efficient sharding
- Architectures where tensor-core throughput matters more than memory
In large-scale LLM hosting scenarios—particularly 70B+ model families—the H200 provides an architectural advantage that is difficult to replicate through scaling alone.
Looking to migrate without overlap costs?
Migration shouldn’t drain your budget. With HorizonIQ’s 2 Months Free, you can move workloads, skip the overlap bills, and gain extra time to switch providers without double paying.
Get 2 Months Free
Looking to migrate without overlap costs?
Migration shouldn’t drain your budget. With HorizonIQ’s 2 Months Free, you can move workloads, skip the overlap bills, and gain extra time to switch providers without double paying.Get 2 Months Free
How do their cluster scaling behaviors differ?
Cluster scaling is where the two GPUs diverge most clearly.
H100 scaling characteristics
- NVLink (900 GB/s) provides extremely fast interconnects
- Ideal for distributed training
- Works well with the NVLink Switch System for large clusters
- Training frameworks already deeply optimized for H100
H200 scaling characteristics
- Reduces the need for large multi-GPU clusters by hosting larger models on a single GPU
- Minimizes multi-GPU tensor parallelism
- Lowers operational complexity for inference workloads
- Simplifies long-context and memory-heavy deployments
In short: H100 = best for scaling out training. H200 = best for avoiding scaling altogether for inference.
How do the H200 and H100 compare for MIG partitioning and security?
Both GPUs support:
- NVIDIA Confidential Computing
- Up to 7 MIG instances
- Strong isolation for multi-workload environments
This makes either GPU suitable for industries requiring strict compliance and workload separation, including:
- Financial services
- Healthcare
- Government and public sector
- Regulated enterprise environments
On HorizonIQ’s single-tenant architecture, MIG is typically used for internal team separation rather than multi-customer tenancy, aligning well with security and predictability goals.
Which GPU is more cost-effective in an enterprise environment?
HorizonIQ provides predictable, transparent monthly pricing for both GPUs, but cost-effectiveness depends entirely on workload:
Choose the H100 when:
- You are training models regularly
- You need NVLink-enabled scaling
- You work heavily with tensor-core-optimized frameworks
- You run scientific or HPC workloads that benefit from FP64 and FP32 performance
Choose the H200 when:
- You are deploying LLMs in production
- You work with models above 70B parameters
- You need larger context windows
- You want to simplify your inference stack or reduce node count
- You want lower inference latency for user-facing apps
HorizonIQ strengthens both options with:
- Predictable monthly pricing
- 9 global regions
- Single-tenant GPU environments
- 100% uptime SLA
- Compass for proactive monitoring and control
- Compliance-ready infrastructure
What’s the best long-term GPU strategy for enterprise AI?
Choose the H200 if your primary workload is LLM inference
It simplifies architecture, supports larger models, and eliminates memory constraints.
Choose the H100 if your primary workload is training
It delivers the strongest tensor-core throughput and multi-GPU scaling efficiency.
Many enterprises benefit from a hybrid approach
Train on H100, deploy on H200. This balances cost, performance, and long-term versatility.
Final Verdict: NVIDIA H200 vs H100?
Both GPUs are exceptional, but designed for different tasks:
- H200 is optimized for large-model inference, RAG pipelines, long-context LLMs, and memory-bound AI workloads.
- H100 is optimized for training, HPC workloads, and multi-GPU scaling, where tensor-core throughput and NVLink performance matter most.
Enterprises running modern AI platforms often pair both: H100 for training pipelines and H200 for production-scale inference. HorizonIQ’s single-tenant GPU infrastructure provides a predictable, compliant, and high-performance foundation for either approach.



