Month: April 2019

The cloud promised it all: flexibility, scalability, agility. These benefits have convinced many enterprises to move their on-premises IT infrastructure to the cloud. And certainly, many found that the cloud offered exactly what they promised.
For others who moved to the hyperscale public cloud—especially those whose applications have steady, predictable workloads or must adhere to strict compliance standards—capturing the benefits of the cloud without running into potential pitfalls has proven difficult.
Even harder still is finding ways to manage costs and get the cloud expertise you need to fully leverage your solutions.
Hosted private cloud is a smart way to get the benefits of the cloud in a right-sized, custom-built deployment—and with the economics to make sure your solution works for you.
Fill out the form below to download our ebook today.
Learn more about hosted private cloud and the economic benefits you can expect from a Virtual Private Cloud or Dedicated Private Cloud, including:
- Resource optimization through rightsizing
- Quick deployment and flexibility for special projects
- Expanded operational capacity
- Efficient use of human capital and minimizing opportunity costs
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


DART Box™ – Cloud Seeding Made Easy
Setting up your backup and disaster recovery data in the cloud—called seeding—is the first step in any business continuity plan. The process has two considerations that we at HorizonIQ treat with utmost care: speed and security.
Our proprietary DART Box™ (Data Acquisition and Recovery Transfer) seeding system is the answer to both, allowing you to safely and securely ship large amounts of data into our enterprise, production-grade cloud storage.

FAQ: Isn’t shipping physical media slower and less secure?
Not necessarily. While creating your first backup over the internet is optimal for small amounts of data, the rate of transfer depends on the congestion of the public network, providers, and routers.
That’s why large datasets in the terabytes can easily take too long for business continuity migration schedules. For security, encryption is typically a safe bet, but there will always be a small risk of the data being intercepted.
Transferring Large Quantities of Data? Use the DART Box™ System.
Large datasets are best seeded with physical media. However, traditional physical media like hard drives, CDs, and thumb drives must be encrypted and securely shipped for maximum peace of mind.
With HorizonIQ’s DART Box system, shipping your organization’s mission-critical data is both safe and simple. We send you specially encrypted 6 TB hard drives in a tamperproof box that includes everything needed to get your business continuity plan moving and digitally secure your data. In addition, the box comes with security measures that will protect your hardware from physical tampering or alert you to any attempts.
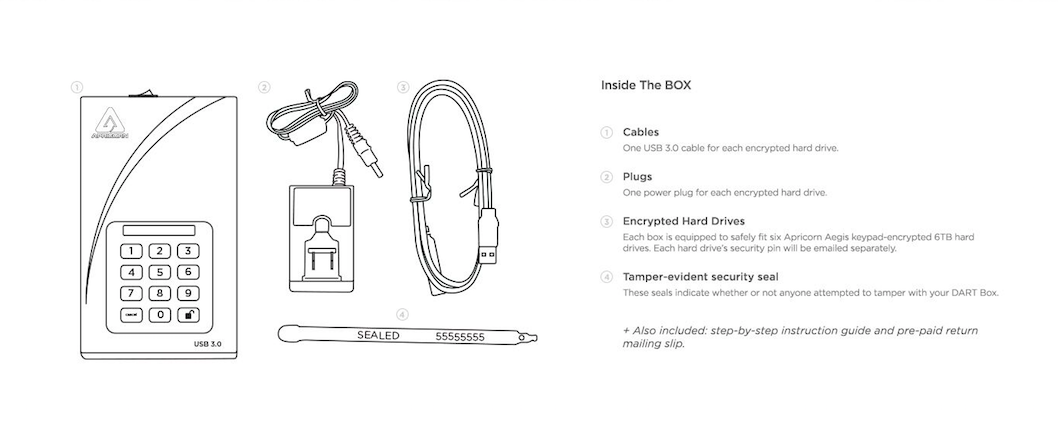
Locally transfer your data, ship it to HorizonIQ, and our data center technicians will take care of the rest. The service is provided free of charge with all HorizonIQ business continuity plans.
Remember, this is a one-time operation: Once the seeding process is complete, you’ll only need to remotely back up the data that changes after the initial transfer. Chat with us to learn more about the DART Box and explore our full suite of security, compliance, and business continuity solutions.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


Announcing HorizonIQ Spend Portability: Agility and Flexibility for Modern IT
As multi-cloud and hybrid IT strategies become standard for the most agile, innovative enterprises, tech leaders must choose solutions that balance the needs of the business today with the agility and flexibility that the rapidly shifting tech landscape demands.
That’s why committing to a data center or cloud solution for multiple years is a common source of consternation for infrastructure and operations (I&O) leaders. If business needs change, decision-makers rightfully fear being locked into a solution or vendor, which may require them to sacrifice agility or devote precious resources to costly, unplanned strategic pivots.
With HorizonIQ Spend Portability, there’s no need to fear.
Our new program provides solution flexibility after you deploy your initial solution. Exchange infrastructure location or hardware a year (or later) into your contract. That way, you can focus on current-state IT needs knowing you can adapt for future-state realities.
What is HorizonIQ Spend Portability?
HorizonIQ Spend Portability is a spend portability program available to new customers. It gives you the option to switch infrastructure solutions—dollar for dollar—part-way through your contract. This will help you avoid environment lock-in and achieve current IT infrastructure goals while providing the flexibility to adapt to whatever comes next.
What solutions are eligible?
HorizonIQ Bare Metal Solutions are eligible for the Spend Portability program. Chat with us to learn more about these services, and how spend portability can benefit your infrastructure solution.
HorizonIQ Spend Portability: Use Cases
A variety of business cases exist for Spend Portability:
- Switch part or all of your current spend to new geographic regions or data centers
- Re-deploy applications on a new hardware configuration
Let’s walk through a few example scenarios.

No.1: Geographic Flexibility
One year after deploying HorizonIQ Bare Metal servers on the U.S. West Coast, a growing SaaS customer sees an increased demand for service in the EMEA region.
Solution
To get closer to their growing user base, the customer shifts part of their deployment to a custom-engineered solution in HorizonIQ’s North London cloud location.

No. 2: Application Best Fit
A HorizonIQ Bare Metal customer needs to decommission legacy workloads and deploy newly architected applications that are better suited to a virtualized environment.
Solution
Rather than spin up new on-demand services with a hyperscale public cloud provider, the customer uses HorizonIQ Spend Portability to reconfigure their Bare Metal server hardware, which provides a scalable, single-tenant environment tailored to the resource needs of the new applications.
To learn more, fill out the form and download the HorizonIQ Spend Portability FAQs.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


How to Defeat Ransomware With Disaster Recovery as a Service
Given the eye-catching headlines and high-profile disasters, ransomware’s ability to wreak havoc probably needs no introduction.
Case in point: The government of Jackson County, Georgia, was recently forced to pay $400,000 in cryptocurrency to a criminal gang that had taken over the network and encrypted their environment, making it completely unusable. Numerous stories like this can be found in headlines across the globe, taken from the experiences of hospitals, universities, and businesses alike.
In 2023, the FBI’s Internet Crime Complaint Center reported 2,825 ransomware attacks, 1,193 of which hit critical infrastructure organizations. Yet these numbers represent only a fraction of the total number of attacks, as the vast majority are never reported to the FBI.
Certainly, ransomware can be devastating, but here’s a secret: It doesn’t have to be.
Disaster Recovery as a Service (DRaaS) allows you to invalidate the threat of ransomware by creating redundancy in your environment. This blog will cover how that works, but first, let’s take some time to understand ransomware.
What Is Ransomware?
Ransomware comes in many forms, but two main varieties have emerged: locker-ware and crypto-ware. Locker-ware involves a hacker taking control of a specific computer or network and then changing passwords so that systems cannot be accessed. Crypto-ware uses encryption techniques to mask all data, rendering it unreadable or unusable.
In both types of ransomware attacks, the criminals extort the organization, offering to unlock the system only after receiving payment (usually in the form of cryptocurrency).
In 2017, ransomware program WannaCry made headlines, infecting an estimated 200,000 computers and netting its creators roughly $300 every time someone chose to pay to decrypt their computers. The real cost, however, is far greater when you include lost productivity and the work required to recover systems impacted by WannaCry. Estimates ranged from hundreds of millions of dollars, even into the billions.
Disaster Recovery as a Service (DRaaS): The Silver Bullet for Ransomware
The first line of defense against any cyberattack or phishing attempt is proper security training for all employees. Foundational security measures include training employees to validate links before clicking them and verifying the identity and legitimacy of senders.
For example, a common trick of hackers involves replacing or switching letters in email addresses to make them appear legitimate. Every organization should have strong group policy objects set for their end users, such as enforcing unique passwords, limiting the installation of software, and disabling forced system restarts.
One of the best ways to protect your organization from ransomware is to put in place Disaster Recovery as a Service (DRaaS) for your critical applications and infrastructure. DRaaS comes in different flavors, and which option you go with will depend on your recovery needs: i.e., Recovery Point Objectives and Recovery Time Objectives. Read our blog on RPO and RTO to learn about what these mean.
Regardless of how often you need to back up (RPO) or how quickly you need your applications to be online (RTO), DRaaS is a straightforward, effective way to neutralize the threat of ransomware.
Here’s how: DRaaS safeguards your physical and virtual systems by creating a functionally redundant environment that you can switch on in the case of any disaster. This minimizes downtime and its impact on your business, while ensuring that you have a “clean” environment that is safe from any malware—ransomware or otherwise.
If attackers do gain control of your systems, all you have to do is contact your DRaaS service provider to begin the recovery process. As a HorizonIQ customer, you can call, email or log in to your portal to immediately let us know what’s happened.
We will work with you to verify what systems or files need to be recovered, confirm the recovery point you need, and then begin a full recovery to overwrite the compromised environment. This process will usually follow a detailed runbook that is collaboratively designed when the DRaaS solution was first implemented as part of our white glove onboarding.
Learn More About HorizonIQ’s Disaster Recovery as a Service
HorizonIQ offers two kinds of Disaster Recovery as a Service: On-Demand DRaaS and Dedicated DRaaS. Both offer redundancy and protection from ransomware—built on our secure, high-performance private cloud. We also offer disaster recovery testing to evaluate your DRaaS solution’s efficacy in a realistic scenario, in addition to a white glove onboarding service.
With a DRaaS solution in place, you can feel confident that your environments are safe from would-be hijackers and, most importantly, costly downtime—whether caused by ransomware, natural disasters, human error, or anything else.
Creating a simple five to 10-page business continuity and disaster recovery plan that is fast, readable, testable, and executable can help you implement a best-fit DRaaS solution. You can get started on creating your plan by downloading our Business Impact Analysis Template:
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected
About Author

The No. 1 Reason Gamers Will Quit Playing an Online Multiplayer Game
What’s the No. 1 reason gamers will quit playing an online multiplayer game?
To find out, INAP surveyed more than 200 gamers and game developers attending GDC 2019, held last month in San Francisco, finding that the two groups don’t exactly see eye to eye. Here’s what we learned about that and more.
Low Lag Vs. Solid Gameplay: Which Matters More?
Among gamers, the top three most common reasons for quitting an online game are high latency/lag (52 percent), followed by bad game mechanics/poor gameplay (43 percent) and poor matchmaking/not enough players (34 percent).

Yet a majority of game developers we surveyed believe that the most common reason gamers would quit playing is bad game mechanics/poor gameplay (56 percent), trailed by high lag/latency (48 percent) and poor matchmaking/not enough players (46 percent).
Put another way, developers overestimated the importance of gameplay and mechanics to their audience by 13 percentage points.
One possible explanation: Though developers are well aware of the impact high latency/lag has on online multiplayer experiences, they are compelled by other factors to focus more on gameplay design, given limited time and resources or the reality of business-driven decisions. The disconnect might also be a factor of the development process or the division of labor, with engineering for online play not being fully integrated with creative design.
What’s clear, however, is that there are risks for developers and studios who underestimate how important a smooth online experience is to gamers.
In fact, low latency is so crucial to online gamers that more than seven in 10 (72 percent) will play a laggy game for less than 10 minutes before quitting. And nearly three in 10 say what matters most about an online game is having a seamless gaming experience without lag.
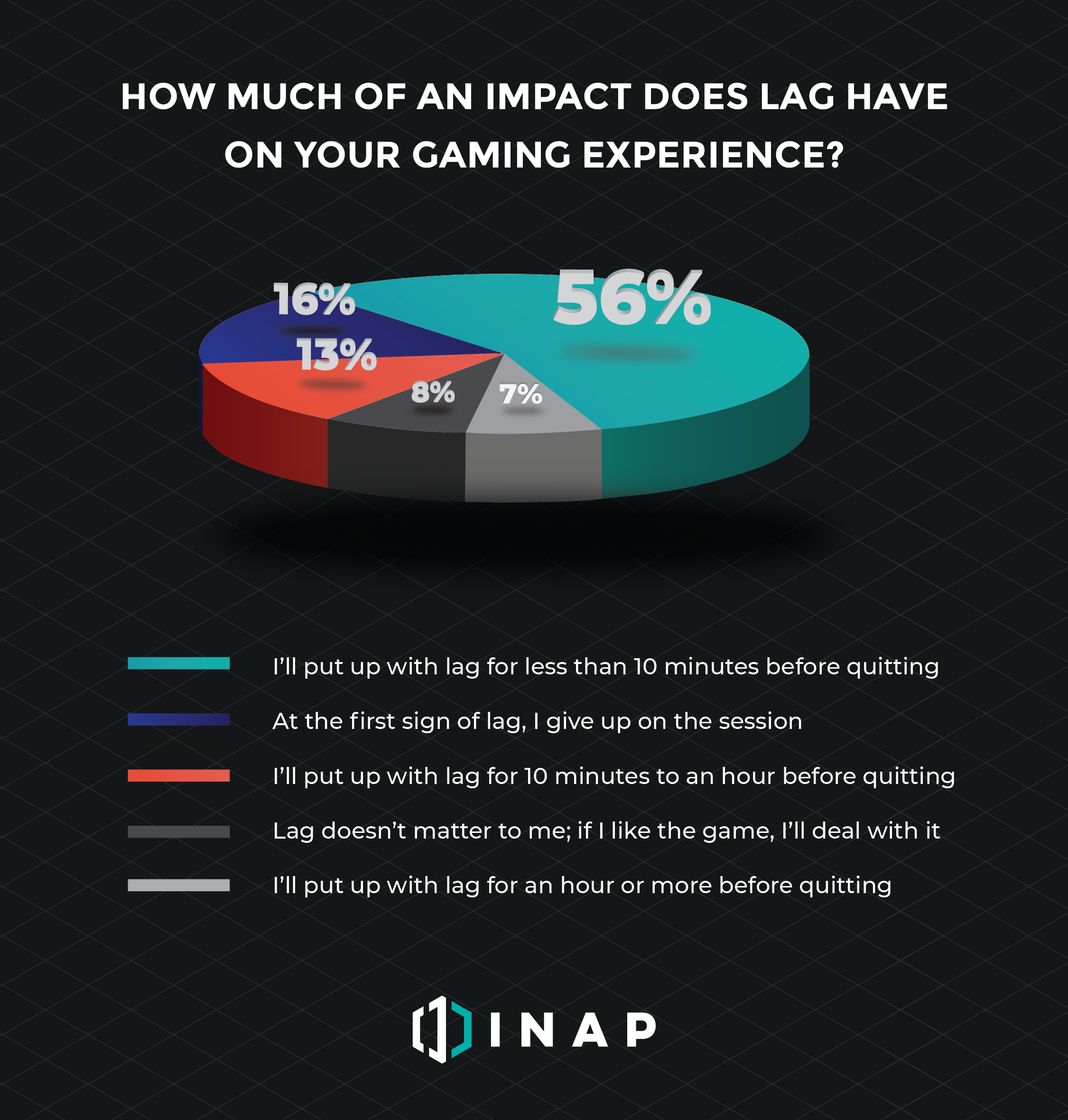
It’s obvious that games can’t be great without excellent gameplay, but if a poor online experience means the vast majority of gamers won’t even play for 10 minutes, then those efforts will go to waste.
The Future of Online Gaming
At the same time, our survey found that developers certainly acknowledge the importance of a good network to high-quality online gaming experiences. Their predictions about the future of online gaming support that.
We asked them what they think the biggest change to online gaming in the next five years will be: Nearly three in 10 (29 percent) believe that gaming will go the same route that Netflix did—100 percent online and available at a moment’s notice.
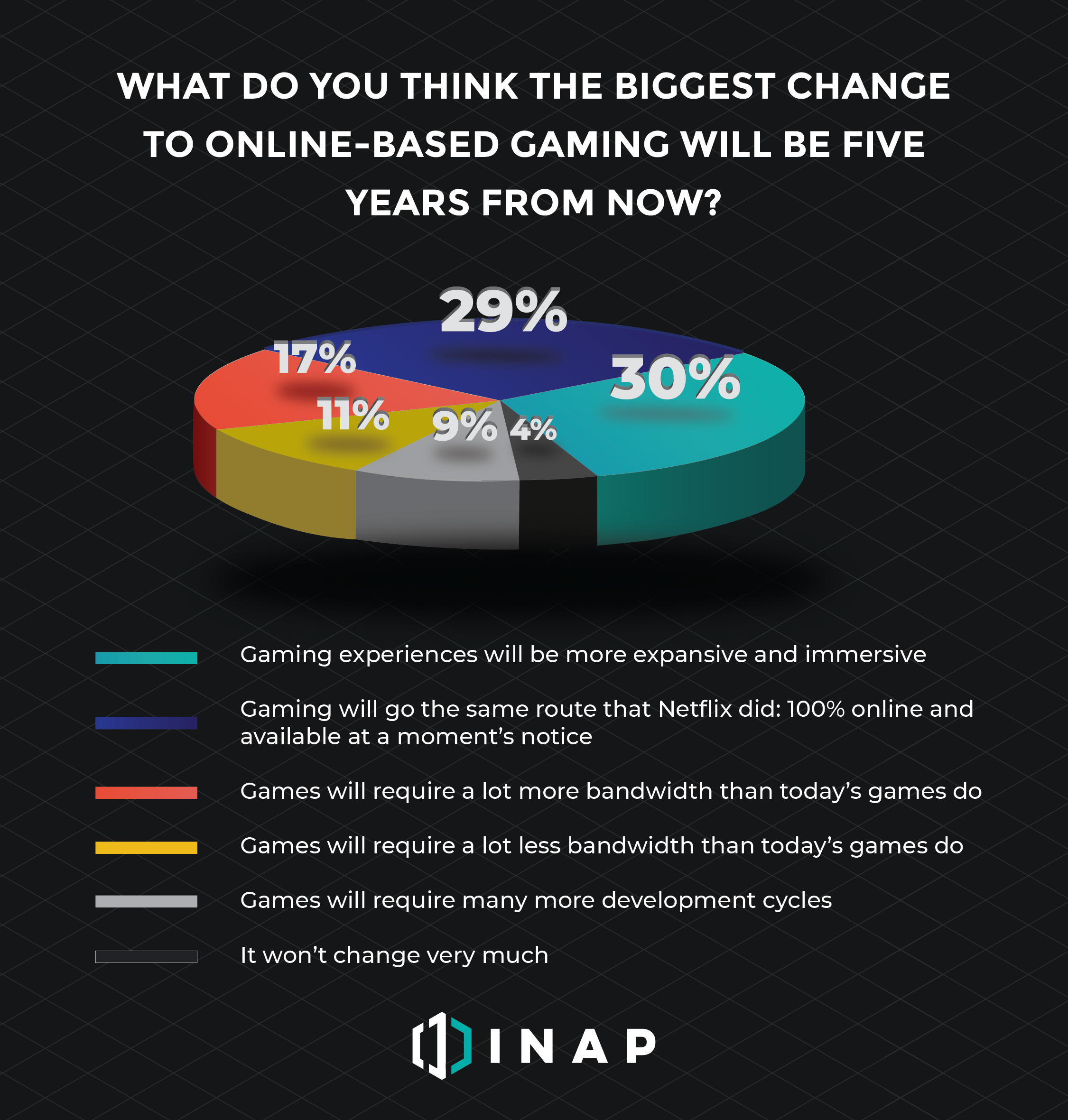
The same amount (30 percent) also believe that the online-based gaming experience will be more expansive and immersive.
These predictions only highlight further the importance of having the technical capabilities to ensure a smooth gaming experience built on a foundation of solid game mechanics, at any time—and able to be experienced unhindered by high latency or lag.
The Challenge of Game Development
Gamers and game developers are equally invested in high-quality gaming experiences. But when it comes to what defines those experiences, they don’t exactly agree. The challenge for developers is to focus on their markers of success—fun concepts, solid game mechanics and compelling gameplay—without letting what matters most to online gamers—low latency/lag—fall by the wayside.
Survey Note: The survey was conducted among ~200 developers and gamers attending the Game Developers Conference 2019, between March 20-22. Data does not reflect a representative sample.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected


About Author

Business Continuity and Disaster Recovery Basics: Testing 101
“Luck is what happens when preparation meets opportunity.” – Seneca
As I covered in another blog post, the first step to any effective business continuity and disaster recovery program is crafting a thoughtful, achievable plan.
But having a great business continuity and disaster recovery plan on paper doesn’t mean that the work is done. After all, how do you evaluate the efficacy of your plan or make adjustments before you actually need it? The answer: by putting it to the test.
Disaster Recovery Plan Testing
I am fond of saying that managed services are a three-legged stool made up of technology, people and processes. If you lose any one leg, the stool falls over. And since an IT department is essentially offering managed services to the wider organization, IT management should think in terms of the same triad.
Let’s break it down:
- Technology: the tool or set of tools to be used
- People: trained, knowledgeable staff to operate the technology
- Processes: the written instructions for the people to follow when operating the technology. (See another blog I wrote for more information: “6 Processes You Need to Mature Your Managed Services.”)
For a disaster recovery scenario, you need to test the stool to make sure that each leg is ready and that the people know what to do when the time comes. One useful tool for this is a tabletop exercise (TTX). The purpose of the TTX is to simply get people thinking about what technology they touch and what processes are already in place to support their tasks.
Tabletop Exercise Steps
Let’s walk through the stages of a typical TTX.
No. 1: Develop a Narrative
Write a quick narrative for the disaster. Start off assuming all your staff are available, and then work through threats that you may have already identified. Some examples:
- Over the weekend, a train derailed, spilling hazardous materials. The fire department has evacuated an area that includes your headquarters, which contains important servers.
- Just 10 minutes ago, your firm’s servers were all struck by a ransomware attack.
- Heavy rains have occurred, and the server room in the basement is starting to flood.
Now, some questions and prompts for your staff:
- What should we do?
- How do we communicate during this?
- How do we continue to support the business?
- What are you doing? Show me! (Pointing isn’t usually polite, but this might be a time to do so.)
- How do we communicate the event to clients, customers, users, etc.?
Going through the exercise, you’ll likely find that certain recovery processes are not properly documented or even completely missing. For example, your network administrator might not have a written recovery process. Have them and any other relevant staff produce and formalize the process, ready to be shared at the next TTX.
Continue this way for all the role-players until your team can successfully work through the scenario. You will want to thoroughly test people’s roles, whether in networking, operating systems, applications, end user access or any other area.
No. 2: Insert Some Realism
Unfortunately, we have all seen emergency situations and scenarios, such as the 9/11 terrorist attacks, where key personnel are either missing, incapacitated or even deceased. In less unhappy scenarios, some staff might not be able to tend to work since their home or family was affected by the disaster. For the purposes of a TTX, you can simply designate someone as being on vacation and unreachable, then have them sit out.
Ask:
- Who picks up their duties?
- Does the replacement know where to find the documentation?
- Can the replacement read and understand the written documentation?
No. 3: “DIVE, DIVE, DIVE!”—Always Be Prepared
Just like a submarine commander might call a crash dive drill at the most inopportune time, call a TTX drill on your own team to test the plan. For this, someone might actually be on vacation. Use that to your advantage to make sure that the whole team knows how to step in and how to communicate throughout the drill. You might even plan the drill to coincide with a key player’s vacation for added realism.
No. 4: Break Away From the Table
Once you’ve executed your tabletop exercise, now it’s time to do a real test! Have your team actually work through all of the steps of the process to fail over to the recovery site.
Again, you will want to test that the servers and application can all be turned up at the recovery environment. To prevent data islands, make certain that users can successfully access your applications’ recovery site from where they would operate during a disaster. Here are some questions for user access testing:
- Can users reach the replica site over the internet/VPN?
- Can users use remote desktop protocol (RDP) to connect to servers in the replica environment?
- If users in an office were displaced, could they reach the replica site from home using an SSL VPN?
No. 5: Bring in a Trusted Service Partner
The help that an IT service provider provides you doesn’t have to stop with managing your Disaster Recovery as a Service infrastructure or environment. With every INAP DRaaS solution, you get white glove onboarding and periodic testing to make sure that your plans are as robust as you need them to be. Between scheduled tests, you can also test your failover at will, taking your staff beyond tabletop exercises to evaluate their ability to recover the environment on their own. Staying prepared to handle disaster is a continuous process, and we can be there every step of the way to guide you through it.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected
About Author

Phoenix Data Center Market Overview
Phoenix, Arizona’s data center market is among the fastest growing in the country, and favorable conditions indicate the boom will not slow down anytime soon.
The Phoenix metro area is only the 11th largest in the U.S. by population but is ranked No. 2 for data center power absorption, according to recent research from JLL, trailing only the hyperscale haven of Northern Virginia. In total, Phoenix has more than 1.6 million square feet of commissioned data center space.
There are multiple factors driving high demand for Phoenix data centers. The city is an increasingly popular destination for California-based companies looking for lower rates on power and real estate. Supply constraints in the Santa Clara, California market are also driving enterprises to seek out alternatives—and Phoenix is picking up the slack.
The nighttime desert climate of Phoenix enables efficient cooling, significantly increasing the power usage effectiveness (PUE) of data centers in Arizona. What’s more, the state of Arizona has capitalized on the favorable climate by offering multiyear incentives for data center investment and operations. Finally, the region faces low risk of natural disasters, making it an attractive location for disaster recovery sites.
All of these factors contribute to why we consider Phoenix among the most important of our 21 strategically located global metros. Currently, we operate in five Phoenix data centers, including our newest Flagship facility.
Considering Phoenix colocation, network or cloud solutions? There are several reasons why we’re confident you’ll call INAP your future Phoenix data centers partner.
High-Density Colocation at INAP’s Newest Flagship Phoenix Data Center

Located in the southeast sector of the Phoenix metro, INAP’s Chandler, Arizona, data center facility at 2500 W Frye Rd, is the most recent Tier 3-design data center to enter our portfolio of Flagships.
The Phoenix data center significantly expands INAP’s Arizona footprint, adding approximately 200,000 gross square feet with up to 18 MW of highly redundant critical power capacity. Additional Phoenix data center specs include:
- High Power Density: 20 kW per rack and up
- On-Premise Substation: Commercial power delivery on-site for high availability
- Available Cooling: 1k tons
- Perimeter Security: K4 security fence with monitored gates
- 36” Raised Floor: 56k square feet
- Critical UPS Power: 5+ MW
- Connectivity: Carrier-neutral Phoenix data center facility with diverse fiber entry
The Phoenix data center is ideal for large-scale or wholesale colocation deployments. INAP offers custom-built private data center suites and cages, suitable for deployments with exacting requirements. The Flagship Phoenix data center is open for business in Q2 2019. We invite you to schedule a tour of this state-of-the-art space, or any of our other data centers in Arizona.
INAP Performance IP + Phoenix = Ultra-Low Latency Network Performance
The high demand for data center solutions in Phoenix means plenty of providers can help you check the requisite Tier-3 data center boxes. But there’s one thing others can’t offer: INAP Performance IP. This proprietary IP service routes tenants’ outbound traffic along the fastest path, providing the lowest latency possible. Every day, INAP’s Performance IP platform executes approximately 15 million route optimizations at our Phoenix data center locations alone.
Connect to INAP’s Scalable, High-Capacity Backbone
Each of INAP’s Phoenix data center locations is connected to our high-capacity private fiber backbone, which links customer environments around the globe. In Phoenix, single points of failure are eliminated by a newly lit dark fiber ring, accessible via our Metro Connect service. With direct backbone connectivity to Los Angeles and Dallas, the high availability fiber rings ensure multiple points of egress for your traffic.
Phoenix: The Ideal Location for Disaster Recovery as a Service (DRaaS)
INAP operates high-performance cloud services—including INAP Disaster Recovery as a Service—at our turnkey Phoenix data center. As a location with a supremely low risk of natural disasters like earthquakes, wildfires or tornadoes, Phoenix is an increasingly popular location for disaster recovery failover sites. What’s more, advancements in cloud hosting and replication make a second data center site for critical systems attainable even for small and mid-size businesses.
Built on our VMware-powered Private Cloud solution, INAP DRaaS offers the service flexibility and expertise required for the most stringent of recovery objectives. Read more about our DRaaS service or get a quote today.
To learn more about our data centers in Arizona visit our Phoenix data centers page.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected


About Author
