Month: October 2020

HCTS 2020 Panel Recap: The Future of Datacenter Networking and Interconnection
Network is integral to the future of hybrid infrastructure solutions, but many companies are just coming to terms with the back-end complexity of how the latest networking technologies figure into the performance, reliability, scalability and visibility of their entire footprint.
“When you introduce hybrid into the mix—and we all see that it is a trend that is accelerating—it’s just making the network more complex. And that’s the area where most enterprises have a skills gap,” said Jennifer Curry, INAP’s SVP, Product & Technology, at this month’s Hosting and Cloud Transformation Summit (HCTS), hosted by 451 Research, part of S&P Global Market Intelligence.
Curry discussed this topic and more on a panel entitled “The Future of Datacenter Networking and Interconnection” during week one of the event.
Networking Needs and Customer Perceptions
During the presentation and panel, hosts Craig Matsumoto and Mike Fratto, both 451 Research senior research analysists, shared how customers are looking for direct connection to public cloud and interconnection from their colocation providers. Furthermore, interconnection services were deemed as a high-priority ask for colocation clients in the context of COVID-19.
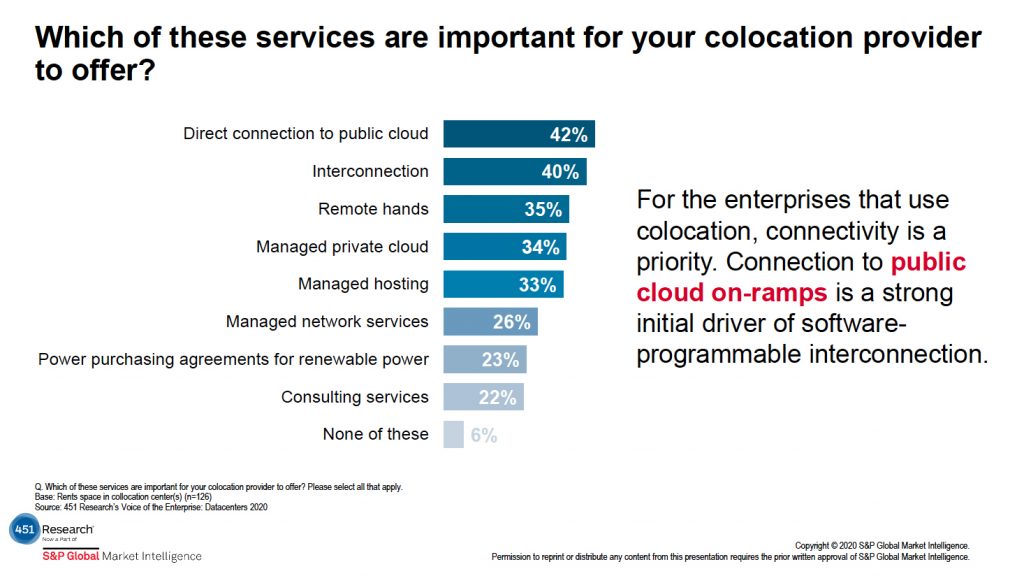
While there is a need for a strong network, enterprise understanding in this area is often lacking. Curry noted that interconnection and network design are the foundation of a successful hybrid environment, but it is easy for people to not think about network, as it is often bundled with a solution from a provider. Behind those solutions, however, network engineers are working hard to make everything work as it should, creating a skills gap in this area within the enterprise.
Despite this gap, recognition that this hybrid world is making the network more complex is on the rise. Traditional networking requirements are still top of mind—performance, reliability, scalability, visibility—but customers have to account for them across multiple platforms and providers. In 451 Research’s Voice of the Enterprise survey, participants named “high complexity” as the biggest pain point related to networking.
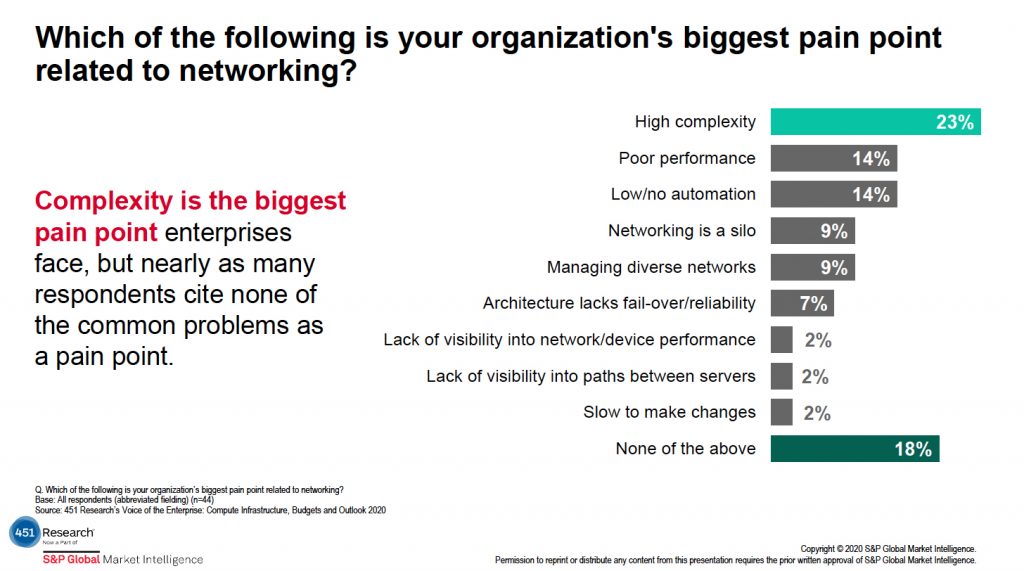
Giving Network Control Back to the Enterprise
With this complexity comes several pitfalls associated with giving control of the network back to enterprise end users. Curry specifically noted the careful balance between cost control and performance, especially with the on-demand nature of the current infrastructure landscape.
“There’s still a lot of focus on cost. If you start to get into the on-demand nature, and you have these tools at the ready that allow you to rapidly scale or have some control over peak usage, the next thing you know, you get a bill where the sprawl is 2-3 times what you thought it was going to be,” she said.
Providers will have to work to get customers comfortable with forecasting their network usage and be able to translate that into the appropriate management. Curry found it interesting that, in the first slide shared above, interconnection and connectivity were top of mind for many participants, but only 26 percent were thinking about network management.
“The easier you make it for customers to make changes, the more you introduce some of that variability that maybe they’re not thinking about,” Curry said.
With a hyper-focus on cost optimization, enterprises can get themselves into situations where they may unintentionally starve some areas of the network. Or, conversely, the costs might skyrocket. Curry noted there are a number of unknowns as self-management tools become more prevalent.
“There are a lot of pitfalls, as well as a lot of opportunity as you get into self-management,” she concluded.
How Network Figures into 5G and COVID-19
In an interview with the INAP ThinkIT blog after the session, Curry shared additional information on how network has and will continue to be impacted by 5G and COVID-19 demands.
The 5G revolution is going to impact multi-tenant data centers (MTDC). Curry noted that 5G spending is predicted to double from 2019 – 2020, but there is still uncertainty around what 5G means to all aspects of infrastructure.
“For data centers, there are the ‘known’ changes that will have to take place, including upgrades and changes to routers, switching, etc.” Curry said. “There is an expectation of changes coming to SDN and NFV (network functions virtualization), but the extent is unknown. There is a breaking point in transporting data from the edge to central data centers, and this is where the MTDC will need to evolve.”
The COVID-19 pandemic has also had an impact on NaaS/on-demand network. Curry stated that while many businesses support remote working, an overnight pivot to full remote workforces further highlighted the need for flexibility and scale in all parts of the infrastructure.
“Some verticals experienced almost overnight saturation of their infrastructure as the daily usage model was completely altered,” Curry said. “And security, while always a priority, resurfaced again as the enterprise was forced to take a new look at the ways their users interact with the systems and data.”
Simplify Your Hybrid Infrastructure with INAP
Networking is an essential element of any successful hybrid strategy, but the complexity doesn’t have to burden your team.
Cut through the complexity and get the performance, reliability, scalability and visibility you need with INAP’s network solutions. Take advantage of our 90+ points of presence, 27 public cloud-on ramps, route-optimized IP transit and global high-speed backbone. To top it off, our experienced solution engineers will design right-sized data center and networking solutions for unique needs.

Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected


About Author


Reduce Your AWS Public Cloud Spend with DIY Strategies and Managed Services
“My AWS bill last month was the price of a car,” a CIO of a Fortune 500 company in the Bay Area said this to me about five years ago. I was new to California and it seemed like everyone was driving a BMW or Mercedes, but the bill could have been equivalent to the cost of a Ferrari or Maserati for all I knew. Regardless, I concluded that the bill was high. Since then, I have been on a mission to research and identify how to help customers optimize their public cloud costs.
Shifting some of your workloads to public cloud platforms such as AWS or Microsoft Azure can seem like common-sense economics, as public cloud empowers your organization to scale resources as needed. In theory, you pay for what you use, thus saving money. Right?
Not necessarily. Unless you are vigilant and diligent, cloud spend through over provisioning, forgetting to turn off unwanted resources, not picking the right combination of instances, racking up data egress fees, and so on, can quickly make costs go awry. But public cloud cost optimization does not have to be esoteric or a long arduous road. Let’s demystify and explore ways to potentially reduce your cloud spend.
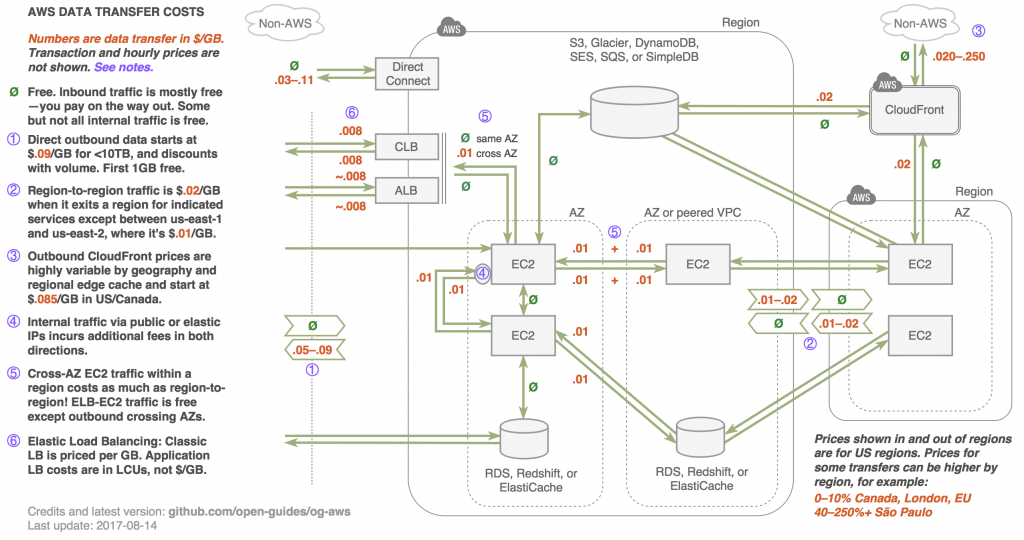
Optimizing Your AWS Data Transfer Costs
For some organizations, a large percentage of cloud spend can be attributed to network traffic/data transfer costs. It is prudent to be cognizant of the data transfer costs within availability zones (AZs), within regions, between regions and into and out of AWS and the internet. Pricing may vary considerably depending on your design or implementation selection.
Common Misconceptions and Things to Look Out For
- Cross-AZ traffic is not free: Utilizing multiple AZs for high availability (HA) is a good idea; however, cross AZ traffic costs add up. If feasible, optimize your traffic to stay within the same AZ as much as possible.
- EC2 traffic between AZs is effectively the same as between regions. For example, deploying a cluster across AZs is beneficial for HA, but can hurt on network costs.
- Free services? Free is good: Several AWS services offer a hidden value of free cross-AZ data transfer. Databases such as EFS, RDS, MSK, and others are examples of this.
- Utilizing public IPs when not required: If you use an elastic IP or public IP address of an EC2 instance, you will incur network costs, even if it is accessed locally within the AZ.
- Managed NAT Gateway: Managed NAT Gateways are used to let traffic egress from private subnets—at a cost of 4.5 cents as a data processing fee layered on top of data transfer pricing. At some point, consider running your own NAT instances to optimize your cloud spend.
- The figure below provides an overview:
Other Cloud Cost Optimization Suggestions by AWS Category
- Elastic Compute Cloud (EC2)
- Purchase savings plans for baseline capacity
- Verify that instance type still reflects the current workload
- Verify that the maximum I/O performance of the instance matches with the EBS volumes
- Use Spot Instances for stateless and non-production workloads
- Make use of AMD or ARM based instances
- Switch to Amazon Linux or any other Operating System that is Open Source
- Virtual Private Cloud (VPC)
- Create VPC endpoints for S3 and DynamoDB
- Check costs for NAT gateways and change architecture if necessary
- Check costs for traffic between AZs and reduce traffic when possible
- Try to avoid VPC endpoints for other services
- Simple Storage Service (S3)
- Delete unnecessary objects and buckets
- Consider using S3 Intelligent Tiering
- Configure lifecycle policies define a retention period for objects
- Use Glacier Deep Archive for long-term data archiving
- Elastic Block Storage (EBS)
- Delete snapshots created to backup data that are no longer needed
- Check whether your backup solution deletes old snapshots
- Delete snapshots belonging to unused AMI
- Search for unused volumes and delete them
Alternatives to DIY Public Cloud Cost Optimization
As I’ve shown, there are more than a few ways to optimize public cloud cost on your own. And if you were to look for more information on the topic, Googling “Optimizing AWS costs” will fetch more than 50 million results, and Googling “optimizing MS Azure costs” will get you more than 58 million results. My eyes are still bleeding from sifting through just a few of them.
Do you really have time to examine 100 million articles? Do it yourself (DIY) can have some advantages if you have the time or expertise on staff. If not, there are alternatives to explore.
Third-Party Optimization Services
Several companies offer services designed to help you gain insights into expenses or lower your AWS bill, such as Cloudability, CloudHealth Technologies and ParkMyCloud. Some of these charge a percentage of your bill, which may be expensive.
Managed Cloud Service Providers
You can also opt for a trusted managed public cloud provider who staffs certified AWS and MS Azure engineers that know the ins and outs of cost optimization for these platforms.
Advantages of partnering with a Managed Cloud service provider:
- Detect/investigate accidental spend or cost anomalies
- Proactively design/build scalable, secure, resilient and cost-effective architecture
- Reduce existing cloud spend
- Report on Cloud spend and ROI
- Segment Cloud costs by teams, product or category
Our experts are ready to assist you. With HorizonIQ Managed AWS, certified engineers and architects help you secure, maintain and optimize public cloud environments so your team can devote its efforts to the applications hosted there. We also offer services for Managed Azure to help you make the most of your public cloud resources.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


Want Disaster Recovery Success? Start with a Business Impact Analysis
Between 2020’s pandemic, hurricanes and wildfires, it’s never been more important to have a solid disaster recovery (DR) plan. INAP’s Jennifer Curry, SVP, Product and Technology, recently spoke with Tech Republic on this very subject. The necessity of DR is widely known, but getting started isn’t always so simple. When a company launches a disaster recovery planning process, it can be daunting task for the IT team to know what systems they need to be made available and in what order. Do we include all the marketing servers? Do we need our HR server right away? The best starting point to plan your DR strategy is to run a Business Impact Analysis (BIA).
A BIA allows a company to better understand what services are needed and in what order they need to continue running. There is no right or wrong process in a BIA, but a few things must be taken into consideration when it comes to putting one together. Check out the list below to get started, and then download INAP’s Business Impact Analysis template, linked below.
Considerations for the Business Impact Analysis
What essential apps and workloads does the company need to provide in the immediate aftermath of a DR scenario?
Which departments would be providing those services? These departments will need to provide information on what systems they require to continue serving internal and external customers. These may include auxiliary systems as well.
Does IT have a list of the systems required by each department to continue business as usual in a DR event?
Each department, no matter what service they provide, needs to be taken into account. This helps everyone understand the many moving parts between different groups. For example, while the accounting group has their own dedicated servers for their accounting app, they may be using a file server for storing data files that’s shared by everyone in the company. In all likelihood, this file server would have been considered non-essential until the BIA was done.
What important internal functions and services are essential to operations?
There may be times when IT assumes a department may not be critical in the plan until they understand all the services it provides. For example, HR payroll systems are essential to a functioning business and needs to be included in the plan. Similarly, marketing and communications systems may need to operate to run critical internal communications during a DR scenario. These functions keep information moving through the necessary channels. Be sure to thoroughly review the functions of all departments.
What kind of timeline should IT follow in a DR scenario?
It is important to understand the timeline in which each app and workload is needed to be brought back online. Some systems simply don’t need an RTO (recovery time objective) of under a few hours. Creating a detailed hierarchy and timeline will save money and logistical headaches. What lower priority systems need to be taken into account? Think about your media storage, archival storage and business intelligence applications and databases and similar systems and where they fit into the plan.
Next Steps
As you use the above considerations to guide your business impact analysis creation, be sure to run your analysis with key team members of each department to create a holistic business continuity document.
Ready to get started on your BIA? Below you can download INAP’s ready-to-use template. You can also check out this post from the ThinkIT blog for more tips on creating this important document.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author
