Month: October 2018

eSports Infrastructure 101: A Closer Look at the Logistics and IT Infrastructure Powering the eSports Industry
If any of your friends are still skeptical about the rise of eSports, just tell them this one statistic: At Wimbledon 2018, men’s singles winner Novak Djokovic earned $2.9 million; the five members of Team OG, who competed in Dawn of the Ancients 2 at a major tournament the same year, received $11.2 million for winning. They played in front a live audience of nearly 20,000 people at Rogers Arena, home of the NHL’s Vancouver Canucks, and more than 15 million people tuned in from around the globe to livestream the event.
eSports is a big deal: The numbers speak for themselves. But what may be less obvious is what goes into putting on live gaming tournaments, especially as their scale rises to the level of traditional sports. What are the needs, whether logistical or technical, and how do they all come together to create a seamless experience?
Logistical Needs
Attracting ever-larger numbers of vested viewers (BusinessInsider puts the number at 300 million today, with the potential to grow to 500 million by 2020), the world of eSports requires and will continue to require a number of large physical locations for tournaments. Currently, these tournaments are held at venues ranging from city-owned civic centers and league sports arenas to private conference halls. Major tournaments have taken place at the famed Staples Center in Los Angeles, the SAP Center in San Jose and Seoul’s World Cup Stadium.
The industry is also giving rise to buildings specifically dedicated to hosting eSports competitions and training. The first of these was Esports Arena in Santa Ana, California, opened in 2015. There is now another Esports Arena at The Luxor in Las Vegas and a new 100,000-square-foot, 1,000-seat venue being constructed in Arlington, Texas.
Some teams have earned enough from sponsorships and team winnings that they build and maintain their own training facilities, which is what Team OMG in China has done. Other teams are earning sponsorships and training resources by partnering with corporations trying to tap into the scene’s seemingly unstoppable growth. Alienware constructed a dedicated training facility for the players and coaches of Team Liquid, showing just one form that such partnerships can take. Their collaboration may serve as a model for other companies looking to get into the space.
Technical Infrastructure Needs
If you have never attended a major eSports tournament (or watched one streamed on Twitch or Youtube), you might be tempted to imagine them as little more than glorified LAN parties, with people lugging around their desktops into dark rooms filled with the sound of clicking, lit only by the glow of computer monitors. While the scene’s DIY ethos hasn’t completely disappeared, major eSports tournaments today are spectacles more closely comparable to professional sports matches than anything else.
The technical needs of these often enormous events have similarly scaled. Tournament hosts range from gaming publishers to companies offering eSports as a Service. And when running tournaments often viewed by hundreds of thousands—if not millions for some of the largest—the technical infrastructure must be sufficiently robust and sophisticated to match.
eSports Hardware and Software Needs
For starters, the software needed to facilitate a successful eSports event must be run both locally on the game host as well as on many other machines at the tournament. One such piece of the set-up is what’s referred to as a heartbeating system. This software auto-detects important moments throughout the game itself (like a player’s aggressive push or key victory moments) so spectators and announcers get the most of out of the viewing experience and don’t miss a thing.
Additional software running in the arena goes to supporting anti-cheating systems. These systems range from preventing alteration of the chat systems to mitigating potential DDoS attacks against specific players or machines—a constant worry, especially with massive prize pools at stake. To ensure the hardware and software are both operating smoothly, additional systems are dedicated to monitoring the gaming experience as well. This monitoring software is generally unique to each game publisher since it is built into each game; it can include monitoring any given player’s hardware or game software characteristics simultaneously to ensure that the tournament is an even playing field for all competitors.
Whether tournament organizers implement a heartbeating system or are merely monitoring for would-be cheaters, data-probing applications are particularly hardware-intensive. They require raw computing power for large amounts of data processing, making bare metal a particularly strong choice. The challenge, however, is striking the right balance between raw performance and service that won’t break the bank. A recent Cloud Spectator report addressed that very challenge, testing AWS, IBM Cloud and INAP Bare Metal, finding our Bare Metal to have up to 4.6x better price performance.
eSports Network and Bandwidth Needs
While a physical facility’s size limits the amount of people who can view the event in person, the internet has no such limit. Broadcasting to popular sites like Twitch, YouTube and Facebook, teams and tournament hosts are able to ensure that everyone who wants to view a match is able to. Some of these matches and pre-tournaments aren’t even held in an event space; they’re held in a small studio or even in a player’s home.
Hardware and software considerations are thus just part of the equation: Large amounts of bandwidth and a reliable network are also needed to both host a successful eSports tournament and ensure a good experience for players and spectators—whether virtual or in-person. For the growing eSports scene, which draws both viewers and competitors from around the globe, a seamless experience can only be achieved through a multifaceted IT approach, marrying together hardware, software and connectivity.
INAP offers it all: Our high-performance servers are paired with our low-latency network and powered by our automated route optimization engine. The online gaming vertical is one of our biggest precisely because our IT solutions are comprehensive and geared toward the kind of performance required for online gaming and live eSports tournaments. It’s also why gaming company Hi-Rez Studios has partnered with us for over 10 years to power their applications.
The rise of eSports only underscores the ways in which the applications of the future demand technology solutions that are not just reliable and high-performance, but also able to scale and adapt to the needs of a fast-moving, interconnected world.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


Edge Computing 101: Latency, Location and Why Data Centers Still Matter in the Age of the Edge
On what seems to be a daily basis, there’s no shortage of new additions to the tech lexicon—whether acronyms, buzzwords or concepts. The “edge” (or “edge computing”) is a somewhat recent inclusion, but what’s most noteworthy is its dizzying diversity of definitions. The edge computing definition can vary wildly depending on who’s talking about it and in what context.
What is Edge Computing?
One of the easiest-to-understand explanations of edge computing can be found in this Data Center Frontier article: “The goal of Edge Computing is to allow an organization to process data and services as close to the end-user as possible.” To take it a step further, you could even say the purpose of edge computing is to provide a better, lower-latency customer experience. (The customer, in this case, is simply defined as whoever needs or requests the data, regardless of what they may be trying to accomplish.)
While much of the discussion around edge computing focuses solely on the edge itself, a holistic edge computing conversation requires us to take a step back and process the importance of all that leads up to it—namely the data center and network infrastructure that supports the edge. When your applications and end users require low latency, taking a look at your whole infrastructure deployment will be more effective than trying to “fix” performance issues with edge computing.
The IT Infrastructure Layers That Get Us to the Edge of Edge Computing
It’s not all about the edge. Here are the layers of IT infrastructure that make or break application performance and end-user experience.
Data Centers/Cloud
This layer is made up of the physical buildings and distributed computing resources that act as the foundation of edge computing deployments. You can’t have edge computing without data centers and cloud computing, just as you can’t have a functional kitchen and appliances without plumbing, electricity and four walls to keep Mother Nature out. What’s important at this layer is proximity and scale, i.e., data centers close to end users that have the capacity to supply fast-growing data processing and storage requirements.
Gateways/Nodes (aka “Fog”)
Fog, a term coined by Cisco, refers to a decentralized computing infrastructure in which data, compute, storage, and applications are distributed in the most logical, efficient place between the edge computing data source and the centralized data center/cloud. The National Institute of Standards and Technology (NIST) only adopted a similar definition in March of this year (2018), which illustrates just how nascent aspects of this model still are. The primary difference to consider when thinking about “fog” versus “edge” is that “fog” is considered “near-edge,” whereas “edge” is considered “on the device.”
Edge
Of all the layers discussed, this one might have the fuzziest definition. For example, from a recent Wells Fargo report: “A user’s computer or the processor inside of an IoT camera can be considered the network edge, but a user’s router, a local edge CDN server, and an ISP are also considered the edge.” Nonetheless, it is safe to think about edge computing in terms of exactly where the intelligence, computing power, and communication functions are situated relative to the end user.
Here’s an example from manufacturing: Many machines now have intelligence built in to control and make decisions at the device. This provides the ability to leverage machine learning that will help plant operators identify “normal” and “abnormal” behaviors. It also adds another layer to control logic and makes it possible for smart machines to use data in decision-making. As a result, analytics for large unstructured data sets—like video and audio—can and will increasingly occur at the edge or other places along the network. This will allow manufacturers to detect anomalies for further examination back at the factory command center.
Latency, Edge Computing, and the Edge-to-Fog-to-Cloud Continuum
Now that we’ve got definitions out of the way, let’s talk about the underpinning factor of the edge—latency. As we discussed earlier and as referenced in the Data Center Frontier article, “The goal of Edge Computing is to allow an organization to process data and services as close to the end-user as possible.” That’s why achieving the lowest possible latency with compute and data processing is of the essence when it comes to the key value proposition of the edge.
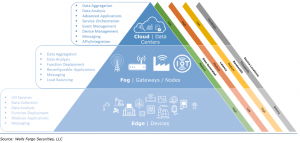
“The Fog” Extends the Cloud Closer to Edge IoT Devices
As you can see in the chart above, latency decreases as you get closer to the edge. That seems pretty simple, right? But there’s a nuance to this that needs to be considered: These layers are all connected and dependent on one another. In other words, you can’t have low-latency edge devices if you do not have the right connectivity further up the chain to the data center and cloud.
As a data center operator and cloud service provider, we’re regularly in conversations with customers and partners about the locations of our 56 global data centers and what kind of latency they can expect to their destinations. High-performance applications require the path from the data center/cloud to the gateway to the edge to have minimal friction (e.g., latency). Thus, if you’re deploying an edge device in my hometown of Chicago, for example, you don’t want the device to be talking to a data center in Los Angeles. You want it, ideally, to be in Chicago. This is true for most workloads and applications today, regardless of IoT or edge capabilities—and it all comes back to providing better, lower-latency customer experiences.
The Edge Is Only as Good as the Rest of Your Network
Whether you’re deploying an IoT project, thinking about how edge computing will impact your business, or simply looking to better understand how to create a better experience for your end users, remember that proximity matters—because latency matters. While pushing edge infrastructure ever closer to end users is one way to reduce network latency, it’s also important to remember that edge computing is only as good as its upstream infrastructure.
For your critical, latency-dependent applications, close edges aren’t enough. You need an entire network built for reliable connectivity and low latency. INAP has a robust global network engineered for scalability, built with the performance our customers need in mind. On top of that, we have an automated route optimization engine baked into all of our products and services that ensures the best-performing path for your outbound traffic.
Edge computing presents an exciting opportunity to explore just how close the technology can get us to the end user’s device, but high-performance applications need high-performance infrastructure from end to end. If your customers need low latency, the edge can’t make up for a poor network—you have to start with a solid foundation of data centers and cloud infrastructure.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


2 Private Cloud Application Models and How to Know Which Is Right for You
When people think about the cloud, what comes to mind is often the public cloud offered by hyperscale providers. This cloud consumption model provides high scalability, flexibility and an on-demand, pay-as-you-go approach. These benefits make the public cloud very attractive.
The private cloud model replicates those benefits in a private or dedicated environment to provide a configuration similar to the public cloud, complete with a notably efficient use of hardware resources. At the same time, private cloud offers SLA-backed service standards, more control over hardware and virtual machines, better control over security and compliance processes, and failover mechanisms.
Not all private clouds are created equal, however, and a plethora of options is available. Let’s start with two major private cloud models.
The Web-Scale Application Model for Private Cloud
This type of application is architected following a web-scale model that does not require a highly available middleware or infrastructure. The application is very scalable and has the built-in intelligence to provide fault-tolerance and mitigate localized disruptions.
For such applications, a simplified scale-out cloud platform is appropriate. Openstack and some similar proprietary cloud offerings are typical examples of this kind of private cloud platform. This type of cloud can be deployed on-premise, in colocation or over a bare metal server offering by an infrastructure provider. It could be self-managed or procured as a service from a cloud management provider.
Openstack does require DevOps and IT expertise to put together the components needed and dispose of otherwise unused parts. As this platform is constantly evolving, some effort is needed to keep the cloud environment up to date and secure. That effort increases dramatically with the complexity of the application deployed and the variety of cloud features used. In case IT staff or expertise is lacking in the organization, such a cloud can be managed by a service provider in-full or in-part, depending on the technical areas that require outside expertise.
Kubernetes is another example. Even though it is not a cloud platform per se, Kubernetes can be used to deploy and manage this type of application with much more ease, albeit with fewer features supported than Openstack.
The Enterprise Application Model for Private Cloud
If the application requires a highly available infrastructure, needs failover support by the underlying platform, makes use of shared SAN storage or requires strict control over processes for security and compliance, then an enterprise-grade cloud platform should be used.
Such applications are typically deployed as managed private cloud environments based on VMware vSphere or Microsoft Hyper-V platforms, with a rich ecosystem of partners and technology providers.
For small and medium-sized companies, this kind of cloud is often procured as a managed service, as its deployment and management call for advanced IT expertise in various technical areas. Additionally, service providers of such clouds are accustomed to IT components and processes needed for the features to support while offering strict control of security, compliance and SLAs. Those providers can be valuable partners and enablers for achieving performance, reliability and compliance.
A Checklist for Selecting the Right Private Cloud Model for Your Business
So how do you know which private cloud is right for you and your applications? Start by looking at your applications’ requirements. Some of the factors to consider are related to the application and workloads themselves, while others are specific to the business structure or IT staff expertise and availability. Here is a list of considerations to help you make your choice:
Scalability
- Does the application scale out seamlessly with many nodes providing the same service for load balancing?
- Is data replicated across multiples nodes?
This scaled-out approach is typical of the web-scale applications and cloud model, where nodes are stateless and a failed node can be easily replaced. If this architecture isn’t built in however, then an enterprise application model is more appropriate.
Business Continuity and Disaster Recovery
- Does your application architecture provide fault-tolerance? In other words, does your application include built-in intelligence to handle failed instances, distribute workloads and move them around seamlessly as needed? If yes, go for a web-scale model; otherwise the cloud enterprise model may provide that layer of reliability.
- Does the application rely on a highly available middleware that guarantees reliability and fault-tolerance? If yes, the enterprise model may be required.
- Is quick recovery from a disaster or a service interruption critical? If yes, the enterprise model would be a better fit.
- Is a very low RPO and RTO required? If yes, an enterprise model would be a strong choice, especially since your managed services provider will likely be able to provide SLA guarantees and offer DRaaS solutions.
- Is your application capable of tolerating massive disruption in a geographical area with no major impact on service delivery? If yes, a web-scale model would work well, with the application architecture itself being built for it.
Compliance
- Does the application require compliance with any regulations such as PCI, HIPAA or other standards that call for strict control on security and management processes? If yes, an enterprise model makes sense, especially with the help of an expert managed services provider.
IT Resources
- Does the enterprise have IT staff with the expertise to manage and maintain the environment and related processes? For a cloud environment, this may include IT, DevOps and even developer teams that might not be considered part of the core business of the organization.
- Does the organization have an IT security team that guarantees the integrity of the IT environment and protects it against ever-escalating security challenges (e.g., DDoS, intrusion, breaches and data exposure)?
A service provider can be valuable for both models. For the web-scale application, a colo or bare metal provider takes the management and servicing of infrastructure off your plate. The cloud platform itself can be deployed and/or managed by a cloud management provider. For the enterprise model, a service provider offers expertise and extensive resources to manage the platform, handle security and compliance processes, in addition to monitoring resources and engaging other solution partners.
The Value of a Trusted Service Provider
If you are considering an infrastructure refresh to take advantage of the efficiency and scalability that cloud technologies deliver, a trusted service provider like INAP can offer a variety of proven infrastructure solutions to address your technical and organizational requirements. Such offerings range from colocation and bare metal cloud for self-managed private clouds to a fully managed enterprise-grade cloud within a dedicated, private environment. If you’re uncertain, INAP can also help you navigate the complexity of the cloud landscape and guide you toward an optimal solution for your current and evolving infrastructure needs.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author