Month: October 2019

IT Horror Stories, Just in Time for Halloween
From out of control on-premise fires to misplaced tequila bottles that delete customer data [NSFW—language!], there’s a lot that can go nightmarishly wrong in the tech world. While we don’t often want to ruminate on what’s beyond our control, Halloween is the perfect time to face our fears, and entertain ourselves in the process.
In celebration of the spooky season, below are IT horror stories to give you the chills, or maybe just a laugh.
Dropped Database
Our first story comes from Paweł Kmieć, a senior managing developer, who shared with ThinkIT an all-important lesson about knowing your environment. Kmieć was developing a reporting application. The deadline was drawing near and everything was going well. It was time to move the application from the development environment into production.
As Kmieć tells it, “I happily launched all necessary data imports and spent quite a lot of time manually verifying and cleaning data afterwards. The day before [the] demo to our CFO, I mistook the dev database with the newly created production database and issued a statement which still haunts me ten years later: DROP DATABASE.”
Kmieć reports that he hasn’t developed in production since this incident.
Beer Goggles
Easy jobs can sometimes end up being harder than expected. Egor Shamin, System Administrator at ScienceSoft, shared with us a story from 2012 at a previous job. He and a coworker traveled to do what he describes as a “cushy job”—building a network for 30 PCs.
The first day of work went smoothly, and they only had to pin out network sockets and install patch panels, so they chose to spend the rest of the night relaxing. After sharing a few drinks together, Shamin turned in for the night, but his coworker kept on drinking.
“We were both late to work the next day, which was already a bad start,” Shamin recounts. “But what made it worse was that we needed to run one more wire, and the line we had physically didn’t allow it. My partner decided that he’d be able to neatly widen the line with the drill. Thanks to the nine beers he’d had the previous evening, all the guy managed to do using the drill was cut down all of the wires.”
The pair ended up working late into the night making wire twists since they didn’t have any other cable. Shamin says that, to his credit, his coworker did most of the job himself. And in the end, the network worked perfectly fine.
Getting Squirrely

For all of our efforts to control our environment, nature often has other plans. Did you know that squirrels are among the reasons that data centers sometimes go down? Reddit user JRHelgeson had a brush with a squirrel squatter himself while moving customer equipment into a new facility.
There were a number of things he saw that could go wrong. The furry creature might burrow under the raised flooring and build a nest in the fiber bundle. Or he might have the run of the data canter by getting up on an overhead ladder. JRHelgeson knew his team had to act fast to evict the gate crasher.
“We had guys with packing blankets moving in from three sides to get him cornered and he scurries up to the top of a rack filled with customer equipment. As they are closing in, the squirrel starts growling and—preparing for a fight—empties his bladder, raining down on the servers in the rack.”
The team finally caught the squirrel and got him out. Fortunately, no real damage was done since the top of the servers were sealed. From that day forward, if the outside door is open, the interior door is closed, or an alarm will go off.
The Little Patching Server That Could
The web has a treasure trove of nightmare stories if you know where to look. The next story, featured on Global Knowledge, was shared by Derrick B., and serves as a reminder to never do patching work in the middle of the business day, even if the patching isn’t expected to have a major impact.
Derrick’s team was all set to patch Windows servers. Change Management approved their patching and timing, which was intended to occur after hours to minimize impact. Everything started off well, until the patch management server crashed and wouldn’t reboot. Calls were put out to hardware support for troubleshooting, but the field tech didn’t arrive until the next day. The tech ran diagnostics and solved the problem, which only led to bigger issues.
“The monitoring console lit up like a Christmas tree and pagers started going off all around the server and application admins’ aisles,” Derrick says. “Servers were going down all across the enterprise. Senior managers started calling to find out what the heck was going on. Customers were being impacted as applications became unavailable.”
It turns out the patching server just wanted to do its job. It has set a flag to run the patching jobs before crashing and picked right up where it had left off as soon as it was repaired.
Not-So-Experimental
Cleaning up databases should always be done with great care. GlowingStart founder Alex Genadinik shared his horror story with Business News Daily, recounting a time when he accidentally deleted around 26,000 business plans on his apps.
“I was cleaning up some old tables in a database and noticed a table with a weird table name. I thought that it was something experimental from a long time ago and deleted it,” Genadinik says. “Then, literally five minutes later, I started getting emails from my app users that their business plans were deleted.”
With the number one function of his apps wiped out, Genadinik had a big problem on his hands. He went to work with his hosing provider and was able to have the database restored within a day after paying a fee. Talk about a scare!
Gone Phishing
 Unfortunately, the next story is becoming an all too common occurrence for IT professionals. Our own Victor Frausto, security engineer, shared a past incident with a phishing email that was spammed to employees from one user’s account. Even though the attempt was caught early and minimized, the resulting work to reset the account and ensure the malicious email didn’t spread made for an eventful day at work.
Unfortunately, the next story is becoming an all too common occurrence for IT professionals. Our own Victor Frausto, security engineer, shared a past incident with a phishing email that was spammed to employees from one user’s account. Even though the attempt was caught early and minimized, the resulting work to reset the account and ensure the malicious email didn’t spread made for an eventful day at work.
“We had to disable the compromised account, scan the laptop, re-enable the account and change the password,” Frausto said. “And then we had to that for anybody who opened the spam email and clicked on the malicious link. Scary!”
Sometimes, the scariest thing in tech can be the feeling that you have to go it alone. Check out HorizonIQ’s managed services and disaster recovery options to get a handle on your IT nightmares!
Happy Halloween!
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected



About Author


A Guide to Evaluating Cloud Vendor Lock-In with Site Reliability Engineering
Adoption of cloud services from the Big 3—AWS, Azure and Google—has outpaced new platforms and smaller niche vendors, prompting evolving discussion around the threat of “lock-in.” Thorough evaluation using common tenets can help determine the risk of adopting a new cloud service.
Vendor lock-in is a service delivery method that makes a customer reliant on the vendor and limited third-party vendor partners. A critical aspect of vendor lock-in revolves around the risk a cloud service will inhibit the velocity of teams building upon cloud platforms. Vendor lock-in can immobilize a team, and changing vendors comes with substantial switching costs. That’s why even when a customer does commit to a vendor, they’re increasingly demanding the spend portability to switch infrastructure solutions within that vendor’s portfolio.
There are common traits and tradeoffs to cloud vendor lock-ins, but how the services are consumed by an organization or team dictates how risky a lock-in may be. Just like evaluating the risks and rewards of any critical infrastructure choice, the evaluation should be structured around the team’s principles to make it more likely that the selection and adoption of a cloud service will be successful.
The Ethos of Site Reliability Engineering
Site Reliability Engineering (SRE), as both an ethos and job role, has gained a following across startups and enterprises. While teams don’t have to strictly adhere to it as a framework, the lessons and approaches documented in Google’s Site Reliability Engineering book provide an incredible common language for the ownership and operation of production services in modern cloud infrastructure platforms.
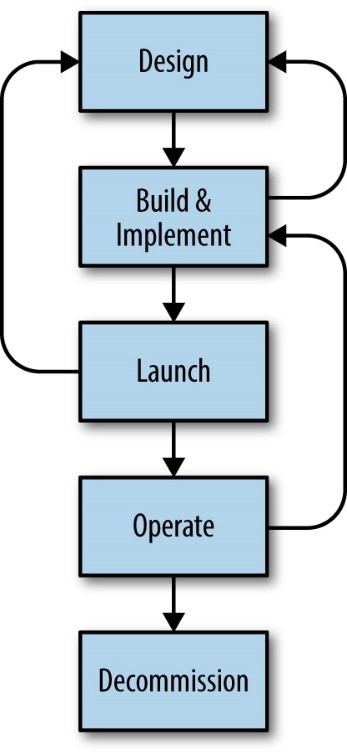
The SRE ethos can provide significant guidance for the adoption of new platforms and infrastructure, particularly in its description of the Product Readiness Review (PRR). While the PRR as described in the Google SRE Book focuses on the onboarding of internally developed services for adoption of support by the SRE role, its steps and lessons can equally apply to an externally provided service.
The SRE ethos also provides a shared language for understanding the principles of configuration and maintenance as code, or at least automation. If “Infrastructure as Code” is an operational tenant of running production systems on Cloud platforms, then a code “commit” can be thought of as a logical unit of change required to enact an operational change to a production or planned service. The number of commits required to enact adoption of a service can be considered a measurement of the amount of actions required to adopt a given cloud service, functionally representing a measurement of lock-in required for adoption of the cloud service.
Combining the principles or SRE and its PRR model with the measurement of commits is a relatively simple and transparent way to evaluate the degrees of lock-in adoption the organization and team will be exposed to during adoption of a cloud service.
Eliminating toil, a key tenet of SRE, should also be considered. Toil is a necessary but undesirable artifact of managing and supporting production infrastructure and has real cost to deployment and ongoing operations. Any evaluation or readiness review of a service must stick to the tenants of the SRE framework and acknowledge toil. If not, the reality of supporting that service will not be realized and may prevent a successful adoption.
Putting Site Reliability Engineering and Product Readiness Review to Work
Let’s create a hypothetical organization composed of engineers looking to release a new SaaS product feature as a set of newly developed services. The team is part of an engineering organization that has a relatively modern and capable toolset:
- Systems infrastructure is provisioned and managed by Change Management backed by version control
- Application Services are developed and deployed as containers
- CI/CD is trusted and used by the organization to manage code release lifecycles
- Everything and anything can be instrumented for monitoring and on-call alarms are sane
- All underlying infrastructure is “reliable,” and all data sets are “protected” according to their requirements
The team can deploy the new application feature as a set of services through its traditional toolset. But this release represents a unique opportunity to evaluate new infrastructure platforms that may potentially leverage new features or paradigms of that platform. For example, a hosted container service might simplify horizontal scaling or improve self-healing behaviors over the existing toolsets and infrastructure, and because the new services are greenfield, they can be developed to best fit the platform of choice.
However, the adoption of a new platform exposes the organization to substantial risk, both from the inevitable growing pains in adopting any new service, and from exposing the organization to unforeseen and unacceptable amounts of vendor lock-in given its tradeoffs. This necessitates a risk discovery process as part of the other operational concerns of the PRR.
Risk Discovery During a PRR
Using the SRE PRR model and code commits as a measurement of change, we should have everything we need to evaluate the viability of a service along with its exposure to lock-in. The PRR model can be used to discover and map specifics of the service to the SRE practices and principles.
Let’s again consider the hypothetical hosted container service that has unique and advantageous auto-scaling qualities. While it may simplify the operational burden of scaling, the new service presents a substantial new barrier to application delivery lifecycles.
Each of the following items represent commits discovered during a PRR of the container service:
- The in-place change management toolset may not have the library or features to provision and manage the new container service, and several commits may be required to augment change management to reflect that.
- More than just eliminating toil, those change management commits are required in order to include the new container service into a responsible part of the CI/CD pipeline.
- The new container service likely has new constraints for network security or API authorization and RBAC, which needs to be accounted for in order to minimize security risk to the organization. Representing these as infrastructure as code can require a non-trivial effort represented by more commits associated with the service.
- The new container service may have network boundaries that present a barrier to log aggregation or access to other internal services required as a dependency for the new feature. Circumventing the boundaries or mirroring dependencies will likely require commits to implement and can be critical to the tenet of minimizing toil.
- Persisting and accessing data in a reliable and performant way could be significantly more effort than any other task in the evaluation. The SRE book has a chapter on Data Integrity that is uniquely suited to cloud services, highlighting the amount of paradigms and effort required to make data available reliably in cloud services. Adoption of those paradigms and associated effort would have to be represented as commits to the overall adoption, continuing the exposure of risk.
- Monitoring and instrumenting, though often overlooked, are anchor tenants of Site Reliability Engineering. Monitoring of distributed systems comes with a steep learning curve and can present a significant risk to the rest of the organization if not appropriately architected and committed to the monitoring toolset.
- Finally, how will the new service and infrastructure be decommissioned? No production service lives forever, and eventually a feature service will either be re-engineered or potentially removed. Not only does the team need to understand how to decommission the platform, but they must also have the tooling and procedures to remove sensitive data, de-couple dependencies or make other efforts that are likely to require commits to enact.
Takeaways from a PRR Using the SRE Framework
While certainly not a complete list of things to discover during a PRR, the list above highlights key areas where changes must be made to the organization’s existing toolset and infrastructure in order to accommodate the adoption of a new container hosting service. The engineering time, as measured by commits, can evaluate the amount of work required. Since the work is specific to the container service, it functionally represents measurable vendor lock-in.
Another hosting service with less elegant features may have APIs or tooling that are less effort for adoption, minimizing lock-in. Or the amount of potential lock-in is so significant that other solutions, such as a self-hosted container service, represent more value for less effort and lock-in risk than the adoption of an outside service. The evaluation can only be made by the team responsible for the decision. The right mode of evaluation, however, can make that decision a whole lot easier.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected

About Author


Dallas, Texas is one of the top three data center markets in the U.S., coming in third just behind Northern Virginia and Phoenix for net absorption rates in 2018[. And with favorable business taxes, low power costs, low risk for disasters, and the availability of trained professionals, it’s no wonder why is a popular data center market.
The major industries in the metroplex include Defense, Finance, Information Technology, Data, Telecommunications and Transportation, and are driving the growth seen in the Dallas data center space. According to JLL, enterprise transactions primarily make up the demand , especially as more companies shift their workloads to off-premise multi-tenant data centers. However, there is chatter that hyperscalers are eyeing the area, and this is something experts are watching closely.
Dallas has also become a destination market as enterprise demand moves out of more expensive markets. It’s appealing to companies looking to be centrally located, and Data Center Hawk notes that the affordable real estate prices and tax incentives are a draw.
CBRE notes that, with the growth and absorption seen in Dallas, the land market for data centers is becoming much more competitive, and it’s anticipated that demand will continue to grow as “AI, automation, IoT, 5G, cloud, gaming and automotive advances” drive new technology requirements.
Considering Dallas for a colocation, network or cloud solution? There are several reasons why we’re confident you’ll call INAP your future Dallas data center partner.
Get the Best of the Dallas Data Center Market with INAP
Ideal for high-density colocation, INAP’s Dallas Data Centers are strategically positioned to leverage the benefits of the region and to offer customers the connectivity they desire. Our flagship Dallas data center, located in Plano, is connected to our downtown data center and POP on a private fiber ring. Customers also have the benefit of connection to all our U.S. POPs and direct connections on our high-performance backbone to to Atlanta, Washington D.C., Chicago, Silicon Valley, Los Angeles and Phoenix.
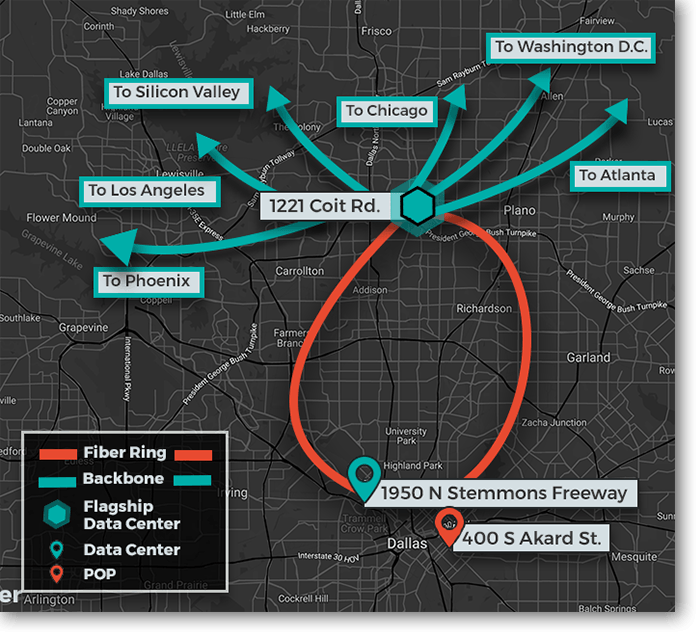
Latency benchmarks on the backbone connection from Dallas:
- Atlanta: Under 21ms
- Washington, D.C.: Under 33ms
- Chicago (using CHG): Under 26ms
- Silicon Valley (using Santa Clara): Under 40ms
- Los Angeles (using LAX): Under 35ms
- Phoenix: Under 29ms
You can rest assured that your data and equipment will be secure in our data centers, with Tier 3 compliant attributes, 24/7/365 onsite personnel and 24/7/365 NOC and onsite engineers with remote hands available. The Dallas data centers are also located outside of flood plain and seismic zones.
At a glance, our Dallas Data Centers feature:
- Power: 5 MW of power capacity, 20+ kW per cabinet
- Space: Over 110,000 square feet of leased space with capacity for 72,000 square feet of raised floor
- Facilities: Tier 3 compliant attributes, located outside of flood plain and seismic zones
- Energy Efficient Cooling: 1,500 tons of cooling capacity, N+1 with concurrent maintainability
- Security: 24/7/365 onsite staff, video surveillance, key card and biometric authentication
- Compliance: PCI DSS, HIPAA, SOC 2 Type II, LEED Green Globes and ENERGY STAR
Download the Dallas Data Center spec sheet here [PDF].
On top of the features at both Dallas-area data centers, our Dallas Flagship Data Center in Plano features:
- 2 individual utility feeds each from a separate distribution stations on a priority Hospital utility grid
- 2 diverse independent fiber feeds with 4 fiber vaults into the facility with 2 Meet Me Rooms
- Suited for deployments of 250kw and up
- Metro Connect fiber enables high performance connectivity in metro market
Download the spec sheet for our flagship Dallas Data Center in Plano, Texas, here [PDF].
Connect with Our Dallas Data Center, Connect with the World
By joining us in our Dallas data centers, you join INAP’s global network, which includes more than 600,000 square feet of leasable data center space and is woven together by our high-performance network backbone and route optimization engine. Our high-capacity network backbone and one-of-a-kind, latency-killing Performance IP® solution is available to all customers, including those in our Dallas data centers. Once you’re plugged into the INAP network, you don’t have to do anything to see the difference.
Across INAP’s extensive network, our proprietary Performance IP® technology makes a daily average of 500 million optimizations per Point of Presence. It automatically puts your outbound traffic on the best-performing route. With INAP’s network, you never have to choose between reliability, connectivity and speed. Learn more about Performance IP® by checking out the video below or test out the solution for yourself by running a destination test.
Dallas is also one of the metro areas in INAP’s network that benefits from Metro Connect, which helps you avoid single points of failure on our high-capacity metro network rings. Metro Connect provides multiple points of egress for your traffic and is Performance IP® enabled. Metro rings are built on dark fiber and use state-of-the-art networking gear.
Our Dallas data centers are conveniently located in the Dallas-Fort Worth metroplex:
- Flagship Dallas Data Center
1221 Coit Road
Plano, Texas 75075 - Dallas Data Center
1950 N Stemmons Fwy
Dallas, Texas 75207 - Data Center Downtown Dallas POP
400 S Akard Street
Dallas, Texas 75202
[i] DFW (Dallas-Fort Worth) Ranks as Second Largest Data Center Market After 53 MW Added to Inventory in 2018, CBRE
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected



About Author

How to Prevent Route Leaks with Inbound and Outbound Route Mapping
As citizens of the internet, it’s our responsibility to be a good neighbor by configuring and managing an autonomous system (AS) that follows proper Border Gateway Protocol (BGP). Improper configuration and management can hold dire consequences, including route leaks.
During the summer, a high-profile route leak event prevented access to Amazon, Facebook, Cloudflare and others over a two hour period. Let’s explore route leaks in greater depth and learn how events like this can be prevented. If you’d like to brush up on BGP and how default BGP can impact your network performance before diving in, you can get a refresher here.
What is a Route Leak?
Simply put, a route leak occurs when internet traffic is routed through unintended paths. More specifically, route leaks happen when an AS advertises prefixes it’s not entitled to advertise.
When an AS advertises prefixes it should not be announcing, some or all traffic destined for the prefix will get redirected to the unwarranted AS, never reaching the intended destination. This is often due to BGP misconfigurations but can also be the result of malicious intent.
The high-profile route leak event over the summer was caused by a small company advertising more specific prefixes introduced by a route optimization appliance. This event could have been avoided if either the small company or its upstream ISPs had followed some basic best practices in their BGP configurations to eliminate the risk of a route leak.
Avoiding Route Leaks with Route Mapping
A small company advertising prefixes to upstream ISPs can use route maps to effectively prevent re-announcing incorrect prefixes. Route maps can be used both on the inbound and the outbound BGP sessions.
In the event mentioned above, an inbound route map should have been used on the BGP session with the route optimizer and set the well-known BGP community for NO EXPORT on routes received. The NO EXPORT BGP community informs the receiving router’s BGP process that it should not advertise the prefixes heard on this session to External Border Gateway Protocol (eBGP) neighbors. This would have prevented any more specific prefixes from being leaked to the upstream ISPs.
Inbound Route Maps
ISPs can use inbound route maps with their customers to limit their expected prefixes. The inbound route map matches only a set of prefixes the customer can announce (as informed by route registries) and allows those routes in the ISP’s route tables.
The ISP can also limit the number of prefixes that a customer can announce before shutting down the BGP session using the maximum-prefix feature. Using maximum-prefix does not necessarily keep an AS from advertising errant routes, but it can limit the scope of a potential route leak.
Outbound Route Maps
Outbound route maps can also be configured by an advertising AS to limit the prefixes that are sent out via BGP. Like the inbound route map on the ISP side of the BGP session, the downstream AS can use an outbound route map to match a prefix list with prefixes a company is permitted to advertise. This prevents any additional prefixes from getting into the ISP’s route tables and out to the larger internet.
Closing Thoughts
Route leaks, and to some degree route hijacking, which is defined by malicious intent, are avoidable as long as AS entities and their upstream providers take the time to configure BGP properly to avoid them. Inbound and outbound route mapping are just a couple of best practices that can eliminate potential route leaks before they become major problems.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected


About Author


19 Cybersecurity Stats to Kickoff National Cybersecurity Awareness Month 2019
“Own IT. Secure IT. Protect IT.” That’s the Department of Homeland Security’s rallying cry for this year’s National Cybersecurity Awareness Month (NSCAM). Held every October, NSCAM brings to the masses what IT professionals and tech executives know all too well: Cyberattacks pose an ever-changing, ever-growing threat to national and economic security, and no household or business is immune.
To kick off National Cybersecurity Awareness Month, we compiled 19 cybersecurity stats that paint a staggering picture of the challenges ahead for businesses and IT professionals.
There are two major undercurrents running through these numbers. First, sophisticated cyberattacks are increasing in frequency and come at a high cost for organizations who are taken offline or lose data. Secondly, although IT pros are well aware of the threat landscape, acquiring the tools, skillsets and resources needed to protect their businesses are significant hurdles. Take a look for yourself below:
- The number of cybersecurity attacks reported to the Pentagon every day: 10 Million (1)
- The ratio of attempted cyberattacks on web applications to successful attacks: 100,000 to 1 (2)
- The percentage of devices at small or medium-sized businesses that run operating systems that are expired or are about to expire: 66% (3)
- The ratio of safe URLs to malicious URLs in 2018: 9:1 (down from 15:1 in 2018) (4)
- The percentage of data breaches involving compromised privileged credentials, such as passwords: 80% (5)
- The number of records stolen or leaked from public cloud storage in 2018 due to poor configuration: 70 million (4)
- The percentage of IT professionals who say protecting their organization from cyberattacks is their top challenge in 2019: 36% (the no. 1 challenge reported) (6)
- The number of unfilled cybersecurity jobs in the United States: 313k (1)
- The estimated number of unfilled cybersecurity jobs worldwide by 2022: 8 million (1)
- The percentage of IT professionals who say the time it takes their teams to address critical patches and updates leaves their organizations exposed to security: 52% (6)
- The average number of days it takes an organization to patch critical CVEs (common vulnerabilities and exposures): 34 (2)
- The estimated percentage of servers not fully up to date on patches, according to IT professionals: 26% (6)
- The number of IT professionals who say they’re very confident their organization has adequate resources, tools and staff to secure its servers, applications and data: 1 in 4 (6)
- The average cost of a successful phishing attack on a single small or medium-sized business: $1.6 Million (1)
- The average annual cost of infrastructure downtime to the average enterprise: $20 million (7)
- The estimated global cost of cybercrime by the end of 2019: $2 trillion (1)
- Estimated annual spending on cloud security tools by 2023: $12.6 billion (8)
- The number of IT professionals who say improving data center security is a primary reason for moving away from on-premise data centers to a remote cloud or colocation facility: 4 in 10 (5)
- The percentage of organizations planning to invest more in IT resilience capabilities such as backup, replication and DR over the next two years: 90% (9)
Resources for Cybersecurity & Business Continuity Protection
While these statistics provide a sobering look at the challenges faced by IT and information security professionals around the globe, the good news is no one has to go it alone. At INAP, we partner with our customers to safeguard their critical infrastructure (and their brand’s reputation) with comprehensive data center and cloud solutions, including managed security services and cloud backup and disaster recovery services.
- Chat now to schedule a complementary IT infrastructure solution consultation
- Browse enterprise-grade managed security solutions for INAP Cloud and INAP Colo
- Sign-up for a free 30-day cloud backup trial, powered by Veeam Cloud Connect (no-credit card required).
- Build your own disaster recovery plan with INAP’s Business Impact Analysis tool
Sources & Further Reading:
- Department of Homeland Security. “National Cybersecurity Awareness Month 2019.”gov.
- “It Takes an Average of 38 Days to Patch a Vulnerability.”
- Alert Logic. “Critical Watch Report: 2019 SMB Threatscape.”
- “Internet Security Threat Report.” February 2019.
- Forrester Research via CloudTech. “Three reasons why killing passwords will improve your cloud security.”
- “The State of IT Infrastructure Management 2018.” December 2018.
- “Cloud Data Management Infographic.” June 2019.
- “Cloud Security Spend Set to Reach $12.6B by 2023.” April 2019
- IDC & Zerto. “The State of IT Reslience Report 2019.”
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected
About Author


Microsoft Licensing Changes: How Will Bring Your Own License in AWS be Affected?
The option to deploy “on-premises” Microsoft software on any provider’s cloud without Software Assurance and License Mobility rights is now a thing of the past. In August, Microsoft updated its licensing terms, which went into effect on October 1, 2019. Under the updated terms, Windows licenses purchased without Software Assurance and License Mobility rights cannot be deployed on services offered by several public cloud providers.
“The emergence of dedicated hosted cloud services has blurred the line between traditional outsourcing and cloud services and has led to the use of on-premises licenses on cloud services,” Microsoft said in a statement when the changes were first announced. “As a result, we’re updating the outsourcing terms for Microsoft on-premises licenses.”
Microsoft noted that these updated terms create a clearer distinction between on-premises/traditional outsourcing and cloud services. Another goal of the changes is to create consistency in licensing terms across multitenant and dedicated cloud services.
The changes, according to Microsoft, will allow the firm to better compete with other dedicated offerings from hyperscale cloud companies. The licensing change is applicable to the following providers:
- Microsoft
- Alibaba
- Amazon (including VMware Cloud on AWS)
What does this mean for you?
As of October 1, 2019, you can no longer bring your own Windows Licensing to the above providers without Software Assurance and License Mobility rights.
This includes, but is not limited to, the following:
- Windows Server Standard/Enterprise
- Windows SQL Server Standard/Enterprise
- System Center Server
Options for Bringing Licenses to AWS
Do you have Microsoft licenses you’ve brought to AWS, or are you currently considering bringing your own license? Consider your options:
Without Software Assurance and licensing purchased prior to October 1, 2019—You can access hardware dedicated to your use if you’re using Amazon EC2 Dedicated Hosts, which makes it possible to bring Microsoft software licenses without Software Assurance or License Mobility benefits. However, these licenses must be purchased prior to October 1, 2019, and cannot be upgraded to versions released after October 1, 2019 in order to stay eligible.
With Software Assurance—With Microsoft License Mobility through Software Assurance, you’re allowed to bring many Microsoft software licenses into AWS Cloud – e.g., for use with Amazon EC2 instances.
Purchase licensing via AWS—Running a cost-analysis with publicly available pricing, this is the least cost-effective option, due to recurring monthly subscription fees. However, it is convenient. Not only does Amazon manage licensing compliance, they support many legacy versions of Microsoft software.
Future Proofing Your Hybrid Cloud
As Microsoft’s licensing changes go into effect, it’s worth doing a cost analysis for future projects. At INAP, we offer a variety of cloud solutions, and our solution engineers are familiar with creating cost-effective and full-feature clouds that best meet your workload and application needs.
With our dedicated private cloud (DPC), virtual private cloud (VPC) and managed AWS and Azure offerings, we can run a cost analysis of multiple solutions, including hybrid DPC/VPC and AWS/Azure. No matter the solution best for your applications, our goal is to ensure you’re able to meet resiliency, scalability and security requirements without sacrificing speed and power.
Explore HorizonIQ
Bare Metal
LEARN MORE
Stay Connected
About Author