Month: May 2025

Google’s Tensor Processing Units (TPUs) and NVIDIA’s Graphics Processing Units (GPUs) are top contenders when choosing hardware for workloads driven by AI. TPUs specialize in tensor processing, and NVIDIA GPUs provide flexibility and a developed software environment.
This comparison between Google’s TPU v6e and NVIDIA’s H100 and H200 GPUs will assist you in choosing which is most suitable for running tasks for artificial intelligence inference, like large language models (LLMs) on cloud or server environments.

What Is a TPU?
Unveiled in 2016, Google’s Tensor Processing Units (TPUs) are tensor operation-specific accelerators best suited for inference workloads in deep learning, for example, neural network inference. The TPU v6e, being one of Google’s sixth-generation Trillium family members, is best suited for cost-effective cloud workloads for AI.
Exclusive to Google Cloud, TPUs are supported by TensorFlow, JAX, and XLA, accelerating Google’s AI initiatives (e.g., Gemini) and delivering high compute efficiency.
Key Features of TPU v6e:
- High Compute: ~2 PFLOP/s FP16 for tensor-intensive workloads.
- Cloud-Native: Strong Google Cloud integration and support for vLLM.
- Cost Efficiency: $2.70/hour per unit Google TPU Pricing for scalable configurations.
What Is a GPU?
A Graphics Processing Unit (GPU) is a specialized processor designed to rapidly manipulate and render images, videos, and animations. NVIDIA’s H100 and H200 GPUs, built on the Hopper architecture, set the industry standard for AI, gaming, and scientific computing.
With large VRAM and a strong software platform (CUDA, PyTorch), the H100 and H200 can be accessed on various cloud and dedicated server platforms and are developer-targeted. Optimized for open-source frameworks like vLLM, they deliver best-in-class inference for AI.
Key Features of H100/H200:
- High VRAM: H100 (80 GB), H200 (141 GB) for large models
- Fast Interconnect: NVLink (~900 GB/s) for Parallelization Efficiency
- Ecosystem: Wide compatibility using CUDA/PyTorch
Looking to migrate without overlap costs?
Migration shouldn’t drain your budget. With HorizonIQ’s 2 Months Free, you can move workloads, skip the overlap bills, and gain extra time to switch providers without double paying.Get 2 Months Free
TPU vs. GPU: What Do They Have in Common?
Both GPUs and TPUs speed up artificial intelligence workloads, specifically deep learning, and exhibit common characteristics:
| Common Feature | Description |
| AI Acceleration | Designed for neural network matrix operations, it supports LLMs such as Gemma |
| Cloud Availability | Accessible through cloud (Google Cloud for TPUs, numerous providers for GPUs) |
| Parallel Computing | Support tensor and pipeline parallelization for large models |
TPU vs. GPU: What’s the Difference?
TPUs are optimized for Google’s environment and tensor operations, while GPUs provide flexibility and more comprehensive software support.
| Aspect | Google TPU v6e | NVIDIA H100/H200 |
| VRAM | 32 GB/unit, requires multiple units (e.g., 8) | H100: 80 GB, H200: 141 GB, fewer units |
| HBM Speed | ≈ 1.5 TB/s, slower, potentially bottlenecked | ~3-4.8 TB/s, faster weight transfers |
| Interconnect | ~450 GB/s, tensor parallel being slower | ~900 GB/s, suitable for large models |
| Compute (FLOPS) | ≈ 2 PFLOP/s, memory-limited | ~1-1.2 PFLOP/s, balanced |
| Cost | $21.60 per hour (8 units), and more expensive per token | $2.99-$7.98/hour, lower per token |
| Software | TensorFlow/JAX, less optimized for vLLM | CUDA/PyTorch, vLLM-optimized |
| Availability | Google Cloud only, limited (e.g., v6e-16/32) | AWS & Azure broad access |
| Parallelization | Pipeline parallel due to insufficient VRAM | Tensor parallel with high VRAM |
| Performance | Fast TTFT (0.76-0.79s, low concurrency) | Slower TTFT (0.9s), higher throughput |
| Ecosystem | Google-focused, less open-source adaptability | Developer-oriented, extensive support |
Pro Tip: LLMs can easily exceed $10k/month at scale due to runaway token, compute, and storage costs. Careful planning around token usage and model selection is crucial to avoid unexpected budget overruns.
TPU vs GPU: Specific Workloads Use Cases
Since the AI workload often determines the decision to use TPUs or GPUs, let’s explore how they perform in common scenarios, with representative metrics to illustrate:
Large Language Model Inference (e.g., LLaMA 70B):
- TPU v6e: Best for low-concurrency inference on Google Cloud, where it results in a Time to First Token (TTFT) of ~0.76s for LLaMA 70B using TensorFlow. Its 32 GB of VRAM is expensive, needing 8 units (256 GB total) to support larger models, making it costly. The throughput is ~120 tokens/s at low concurrency.
- NVIDIA H100/H200: Optimal for high-throughput inference, processing ~150 tokens/s for LLaMA 70B under PyTorch/vLLM on AWS. The H200’s 141 GB of virtual memory accommodates bigger models with fewer units to minimize complexity. TTFT is not as fast (~0.9s) but is more scalable to support multiple users concurrently.
Small Language Model Inference (e.g., Mistral 7B, LLaMA 2 13B):
- TPU v6e: Efficient for batch inference of smaller models using TensorFlow or JAX. TTFT is typically <0.3s, and throughput can exceed 300 tokens/s when the model fits in a single 32 GB TPU slice. However, limited framework support outside Google Cloud may restrict portability.
- NVIDIA H100/H200: Excels in small model deployment with vLLM or TensorRT-LLM. Throughput often surpasses 400 tokens/s on a single GPU. Multi-instance GPU (MIG) support allows deployment of multiple models or replicas on a single unit, enhancing cost-efficiency and concurrency.
Computer Vision (e.g., ResNet-50 Training):
- TPU v6e: Capable of tensor-heavy workloads such as training ResNet-50, utilizing ~2 PFLOP/s of FP16 compute. Tops at ~1,200 images/s on Google Cloud using JAX, but is Google-centric in setup, which limits flexibility.
- NVIDIA H100/H200: Provides ~1,000 images/s for ResNet-50 using CUDA, but its larger ecosystem (e.g., PyTorch) makes it easier to integrate across platforms such as Azure. High VRAM minimizes memory bottlenecks for large data sets.
High-Concurrency Serving (e.g., Chatbot APIs):
- TPU v6e: Less preferable owing to pipeline parallelization, which restrains scalability for high-concurrency workloads. Most suitable for Google-integrated, low-latency inference.
- NVIDIA H100/H200: Best suited for high-concurrency, supporting ~50 users concurrently with sustained throughput of ~140 tokens/s thanks to tensor parallelization and NVLink.
Pro tip: Select TPUs for low-latency, Google-optimized LLM inference or tensor-intensive training. Choose GPUs for high-throughput, multi-user inference or cross-platform support.
TPU vs GPU Ecosystem Integration and Development Experience
The development workflow and software ecosystem greatly influence your experience with TPUs or GPUs:
Google TPU v6e:
- Integration: Tight integration with Google Cloud, needing TensorFlow, JAX, or XLA. Setup is optimized for Google’s ecosystem (e.g., Vertex AI, Gemini), but support for independently maintained open-source tools like vLLM is not as mature, tending to require custom setup.
- Learning Experience: Steeper learning curve owing to Google-specific frameworks. Fewer community resources than GPUs, limited to Google’s documentation for debugging. Strengthened integration into MLOps (e.g., Kubeflow) is Google Cloud specific as well.
- Ideal For: Teams that are currently on Google Cloud or creating in-house AI using TensorFlow/JAX.
NVIDIA H100/H200:
- Integration: Extremely flexible, supporting CUDA, PyTorch, and vLLM on multiple clouds. Native integration with open-source MLOps platforms such as MLflow or Kubeflow, and strong support for frameworks like Hugging Face.
- Developing Experience: Developer-friendly with extensive community support, tutorials, and pre-existing libraries. Debugging is simpler owing to mature tools as well as higher adoption. Setup is trivial on platforms such as RunPod, and there is little vendor lock-in.
- Ideal for: Teams that require cross-platform support, open-source frameworks, or quick prototyping.
TPU vs. GPU: What’s Best for You?
Select Google TPU v6e if:
- You’re in Google Cloud and use TensorFlow/JAX
- You require high compute for tensor operations
- You focus on scaling within Google’s infrastructure
Select NVIDIA H100/H200 if:
- You require flexibility between cloud providers
- You employ open-source frameworks such as PyTorch/vLLM
- You need high VRAM for tensor parallelization
How HorizonIQ Can Help With Your AI Project
Choosing between TPUs and GPUs is just the beginning. Successfully deploying AI—whether for inference, training, or edge applications—requires the right infrastructure, orchestration, and cost optimization strategies.
At HorizonIQ, we help businesses:
- Right-Size Infrastructure: We evaluate AI workloads against bare metal servers, cloud GPUs, or private clusters for optimal cost-to-performance ratios.
- Deploy to Cloud or Bare Metal: Our worldwide infrastructure enables deployment of NVIDIA GPUs on public cloud, private cloud, and high-performance bare metal—a combination of flexibility and control you can leverage.
- Manage Hybrid Environments: Integrating Google Cloud TPUs into your NVIDIA GPU clusters? We craft hybrid environments that feature unified orchestration and observability.
Be it scaling up a chatbot, optimizing an SLM, LLM, or training visual models, our experts assist you in choosing and setting up the perfect stack to match your AI objectives.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected



About Author


What Is Edge AI? A Guide to Smarter, Faster, More Secure AI Deployment
Imagine a factory floor that identifies defects in real-time or a hospital monitor that warns of patient deterioration before a nurse reaches the bedside. This is the potential of Edge AI: technology that brings artificial intelligence to the devices and systems that produce the data. It is no longer necessary to send the information to the cloud and wait. Decisions occur where the data comes from, with speed and accuracy.
As more people adopt AI, particularly within industries where every second counts, Edge AI is becoming essential for safe and scalable operations.
What Is Edge AI?
Edge AI refers to deploying artificial intelligence models locally on edge devices like routers, sensors, or on-prem servers instead of in public clouds or centralized data centers. It’s intended to process and make decisions based on data closer to its original location.
Key benefits:
- Low Latency: Decisions happen within milliseconds.
- Enhanced privacy: Sensitive information remains on-site.
- Offline capability: Operates without continuous internet connectivity.
- Cost savings: Minimizes the costs of data transfer and cloud compute expenses.
Why is Edge AI Important?
Public clouds aren’t built for environments that demand real-time performance and strict regulatory compliance. Several of our healthcare, manufacturing, and finance customers share the same concern: escalating workloads, accelerating costs, and security threats.
Edge AI solves multiple issues:
- Ensures adherence to compliance requirements such as HIPAA, GDPR, and SOC 2
- Enhances cost predictability by removing surprise cloud costs
- Ensures that operations run even under low-bandwidth conditions
- Limits bandwidth usage by filtering the data before transmission.
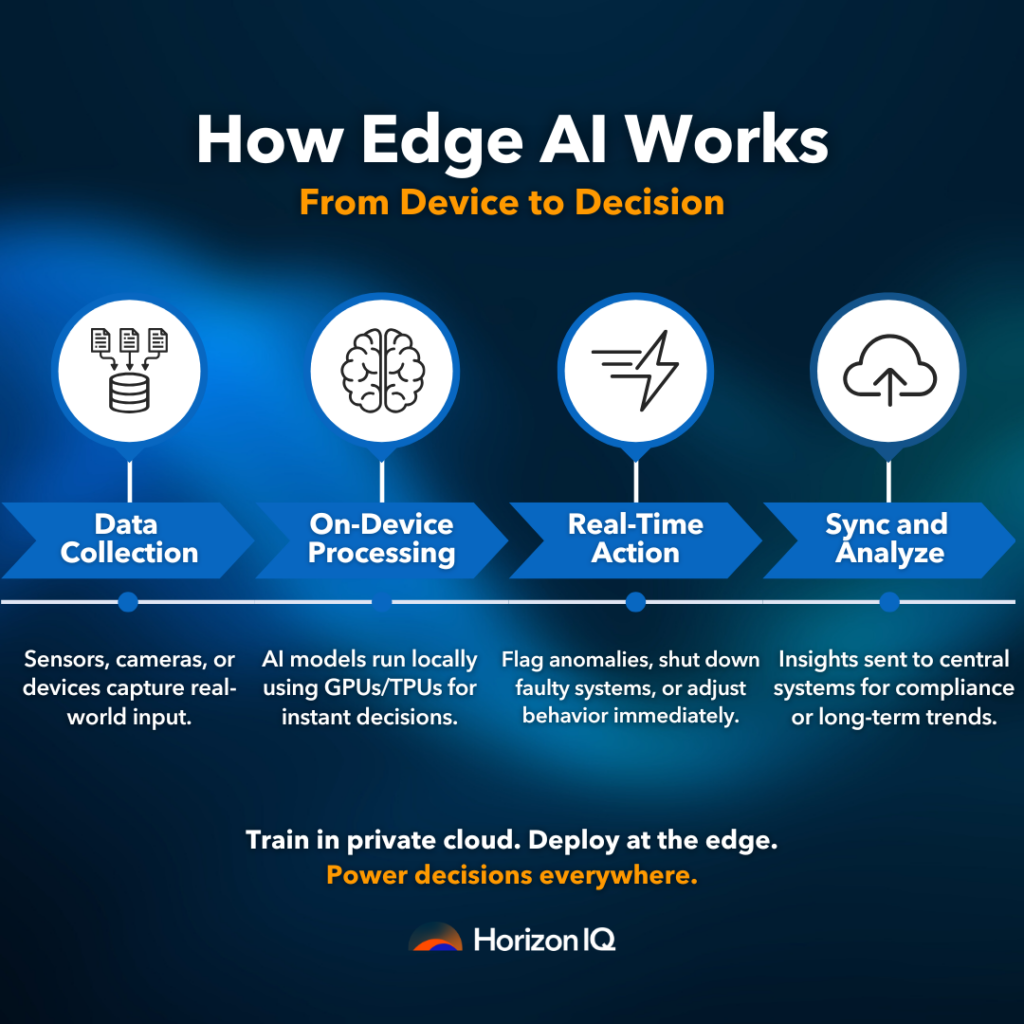
How Does Edge AI Work?
Edge AI begins with the collection of data at its source with sensors, cameras, or edge devices. Rather than shipping this information up into the cloud, a local machine learning model makes the analysis locally on the device with onboard computability, such as GPUs or TPUs.
This facilitates real-time action, such as turning off faulty equipment or alerting to abnormalities in real time. Devices themselves may also stream findings into a centralized system for more extensive analysis or demonstrability.
As described in the context of Intel’s Edge AI overview, this architecture is optimized for lower latency, increased efficiency, and reduced bandwidth requirements.
To enable this model, we provide trusted infrastructure that enables businesses to train their AI in private clouds and deploy quick and light inference engines at the edge.
What Are Applications of Edge AI Across Industries?
Healthcare
Hospitals and other healthcare organizations can perform image scanning or vital monitoring in real time and store sensitive patient information on premises. They receive quicker diagnoses, lower critical care latencies, and complete HIPAA adherence.
Healthcare’s edge AI facilitates privacy by design with its ability to enable organizations to mitigate risks and improve outcomes.
Finance
Banks can spot fraud on the premises without passing vulnerable client information on to third parties.
Institutions can respond instantly to suspicious transactions by using AI models on the edge of the system. The reliance on high-latency cloud infrastructure is minimized.
Manufacturing
Locally deployed predictive maintenance models can spot issues before they cause machines to break down, eliminating expensive downtime.
Real-time monitoring of equipment performance is provided by edge AI with automatic responses when experiencing early warning signs. Operational risk is minimized, and manufacturers’ uptime is optimized.
Retail
Smart cameras and shelf sensors powered by the edge enhance inventory accuracy and shrinkage prevention in real time. The technology also enables personalized consumer experiences that allow for context-based marketing and real-time price adjustment.
According to Forbes, Edge AI is enabling retailers to integrate security, efficiency, and consumer interaction on the sales floor.
Looking to migrate without overlap costs?
Migration shouldn’t drain your budget. With HorizonIQ’s 2 Months Free, you can move workloads, skip the overlap bills, and gain extra time to switch providers without double paying.Get 2 Months Free
Building a Secure, Compliant Edge
Edge AI facilitates a new-age cybersecurity stance by restricting the movement of data, minimizing the number of attack surfaces, and following trends Gartner lists as critical, including distributed decision-making, identity-first protection, and adaptive infrastructure.
It lessens the exposure by processing information locally instead of passing it over networks, something that lessens the possibilities of danger and accelerates response time.
HorizonIQ’s private cloud platform amplifies this strategy with its provision of dedicated environments with built-in support for compliance.
With HorizonIQ, you can:
- Maintain data within given geographic limits
- Implement robust encryption and segregate workloads
- Track performance and risk using Compass
- Smoothly integrate core and edge environments
How Does HorizonIQ Enable Edge AI?
Edge AI needs the appropriate foundation. We offer infrastructure purpose-built for AI deployment as well as safe single-tenant environments optimized for light AI workloads.
Our GPU clusters, powered by NVIDIA, can be customized according to your requirements, ranging from as low as three nodes for small projects and up to hundreds of GPUs for bigger projects. Having this flexibility guarantees that your edge AI projects run both efficiently and economically.
Our infrastructure accommodates:
- Variety of workloads such as small language models (SLMs), computer vision, anomaly detection, generative AI, and autonomous systems.
- Specialized servers providing stable computer performance with low latency and high throughput for real-time inference.
- Compatibility with the leading frameworks, i.e., TensorFlow, PyTorch, and Hugging Face, to ensure smooth integration.
- Scalable architecture that enables starting small and scaling up with no platform changes.
- Enterprise-level security and compliance to facilitate sensitive or regulated applications.
By opting for HorizonIQ, you get a trusted partner ensuring high-performance, scalable, and secure infrastructure for your edge-based AI projects.
Final Thoughts
Edge AI is not just a trend; it is a strategic path towards quicker, more protected, and more responsive business practices. Organizations that embrace it are most likely to become the leaders in their sectors.
We’re here to deliver the infrastructure and support to make that a reality. With the right foundation in place, you’re able to deploy AI where it is most valuable and unlock real-time intelligence without losing control, performance, or compliance.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected
About Author

What’s the difference between SLM vs LLM? The debate between Small Language Models (SLMs) and Large Language Models (LLMs) has caused many organizations to rethink their AI strategy to reduce costs, improve speed, and enable private, task-specific AI.
SLMs are gaining traction for their efficiency and specialized capabilities, while LLMs remain the go-to choice for broad, general-purpose AI tasks.
Let’s explore SLMs and LLMs’ key differences, use cases, and how to choose the right model for your next AI project.

What are Small Language Models (SLMs)?
A Small Language Model (SLM) is a lightweight version of a Large Language Model (LLM). SLMs contain fewer parameters and are trained with higher efficiency.
Whereas LLMs such as GPT-4 is rumored to have 1.76 trillion parameters and enormous training bases covering the entire internet. SLMs usually have less than 100 million (some have 10–15 million).
What are the advantages of SLMs?
- Faster inference: Reduced computational requirements enable quicker responses.
- Lower resource usage: Run on edge devices, mobile phones, or modest hardware.
- Domain-specific customization: Easily fine-tuned for niche applications like healthcare or finance.
- Energy efficiency: Consume less power, supporting sustainable AI deployments.
A Quick Look at Popular SLMs
| Model | Parameters | Developer |
DistilBERT |
66 million | Hugging Face |
ALBERT |
12 million | |
ELECTRA-Small |
14 million |
What are Large Language Models (LLMs)?
A Large Language Model (LLM) is a deep learning model trained on vast datasets to understand and generate human-like text across a wide range of topics and languages. LLMs are characterized by their massive parameter counts and broad general-purpose capabilities.
What are the advantages of LLMs?
- Broad general knowledge: Trained on large-scale internet data to answer diverse questions.
- Language fluency: Capable of generating human-like text, completing prompts, and translating between languages.
- Strong reasoning abilities: Perform logical inference, summarization, and complex problem-solving.
- Few-shot and zero-shot learning: Adapt to new tasks with minimal examples or none at all.
A Quick Look at Popular LLMs
| Model | Parameters | Developer |
Grok 3 |
2.7 trillion* | xAI |
GPT-4 |
1.76 trillion* | OpenAI |
PaLM 2 |
540 billion | |
LLaMA 3.1 |
405 billion | Meta |
Claude 2 |
200 billion* | Anthropic |
*Estimated, not officially confirmed
Looking to migrate without overlap costs?
Migration shouldn’t drain your budget. With HorizonIQ’s 2 Months Free, you can move workloads, skip the overlap bills, and gain extra time to switch providers without double paying.Get 2 Months Free
What are SLM vs LLM key differences?
1. Model Size and Complexity
LLMs excel at general-purpose tasks like writing, translation, or code generation, but require significant computational resources—increasing costs and latency.
SLMs, with their leaner architecture, are purpose-built for specific tasks—offering speed and efficiency.
2. Training Strategy and Scope
One of the most notable distinctions lies in how these models are trained:
- LLMs like GPT-4 are trained on vast collections of data—billions of web pages, books, codebases, and social media content—creating a generalist AI that can answer almost anything.
- SLMs, are usually trained on niche datasets, such as legal contracts, healthcare records, or internal enterprise documents.
These differences in training scope impacts performance, such as:
- LLMs excel at general knowledge but are prone to “hallucinations” in specialized fields.
- SLMs, when fine-tuned properly, deliver greater accuracy in domain-specific tasks.
Example: To remain accurate and compliant, a hospital might use a GPU-powered private cloud trained on proprietary data and clinical guidelines to answer staff questions about treatment plans.
3. Inference and Deployment
SLMs shine in the following deployment scenarios due to their compact size:
- Edge and mobile compatibility: Run locally on IoT devices or smartphones.
- Low latency: Enable real-time interactions, critical for applications like virtual assistants.
- Energy efficiency: Ideal for edge computing with minimal power consumption.
LLMs often require many high-performance GPUs, large memory pools, and cloud infrastructure, which can be costly and complex.
Pro tip: HorizonIQ’s AI private cloud addresses these challenges by offering as small as 3 dedicated GPU nodes with optional scalability into the hundreds. This supports both SLMs and LLMs with seamless compatibility for frameworks like TensorFlow, PyTorch, and Hugging Face.
SLM vs LLM real-world use cases
The value of any AI model lies not just in its architecture, but how it performs under real-world conditions—where trade-offs in speed, accuracy, and scalability come into focus.
| Use Case | Best Fit | Why |
Virtual assistants on mobile |
SLM | Low latency, battery friendly |
General-purpose chatbots |
LLM | Broader knowledge base |
Predictive text/autocomplete |
SLM | Fast and efficient |
Cross-domain research assistant |
LLM | Needs context across fields |
On-device translation |
SLM | Works without internet |
Customer support (niche) |
SLM | Trained on product FAQs |
What are SLM vs LLM pricing differences?
SLMs and LLMs differ significantly in pricing, with SLMs offering cost-effective solutions for lightweight applications. LLMs command higher costs due to their extensive computational requirements.
| Cost Factor | SLM | LLM |
API Pricing |
Lower cost due to smaller model size and lower usage | Typically priced per token: $0.03 per 1,000 tokens (input) and $0.06 per 1,000 tokens (output) for GPT-4. |
Monthly Subscription Plans |
Less relevant due to smaller usage needs | OpenAI’s GPT-4 could cost up to $500 per month for higher usage tiers. |
Compute Costs (Cloud-Based) |
Lower infrastructure requirements | High-end dedicated GPUs (e.g., NVIDIA H100) can cost around $1500 – $5000 per month. |
GPU/TPU Usage |
Not always needed or much cheaper if used | Ranges from $1 – $10 per hour, depending on GPU/TPU model and region. |
Data Storage |
Lower due to smaller model and training data | Typically around $0.01 – $0.20 per GB per month, depending on provider. |
Data Transfer |
Less significant for small models | Data transfer fees can add up to $0.09 per GB for outbound data. |
Predictability of Costs |
More predictable due to lower resource requirements | Can be unpredictable due to scaling usage, with costs scaling quickly as usage increases. |
Estimated Total Monthly Cost |
Typically under $1000/month for most use cases | Can exceed $10,000 per month, depending on token usage, GPU, and storage needs. |
SLM vs LLM: Which should you choose?
The decision between an SLM and an LLM depends on your use case, budget, deployment environment, and technical expertise.
However, fine-tuning an LLM with sensitive enterprise data through external APIs poses risks. Whereas SLMs can be fine-tuned and deployed locally, reducing data leakage concerns.
This makes SLMs especially appealing for:
- Regulated industries (healthcare, finance)
- On-premise applications
- Privacy-first workflows
| Criteria | Recommended Model |
General-purpose AI |
LLM |
Edge AI |
SLM |
Purpose-built AI |
SLM |
Budget constraints |
SLM |
Need for broad context |
LLM |
Domain-specific assistant |
SLM |
Scaling to millions of users |
LLM |
On-device privacy |
SLM |
Pro Tip: You can start with a pre-trained SLM with only a single CPU, fine-tune it on proprietary data, and deploy it for specific internal tasks like customer support or report summarization. Once your team gains experience and identifies broader use cases, moving up the AI model ladder from SLM to LLM becomes a more strategic, informed decision.
Want to build smarter AI applications?
Deploying AI workloads requires a trusted infrastructure partner that can deliver performance, privacy, and scale.
HorizonIQ’s AI-ready private cloud is built to meet these evolving needs.
- Private GPU-Powered Cloud: Deploy SLM or LLM training and inference workloads on dedicated GPU infrastructure within HorizonIQ’s single-tenant managed private cloud—get full resource isolation, data security, and compliance.
- Cost-Efficient Scalability: Avoid unpredictable GPU pricing and overprovisioned environments. HorizonIQ’s CPU/GPU nodes let you scale as needed—whether you’re running a single model or orchestrating an AI pipeline,
- Predictable, Transparent Pricing: Start small and grow at your pace, with clear billing and no vendor lock-in. We deliver the right-sized AI environment—without the hyperscaler markups.
- Framework-Agnostic Compatibility: Use the AI/ML stack that works for your team on fully dedicated, customizable infrastructure with hybrid cloud compatibility.
With HorizonIQ, your organization can deploy SLMs and LLMs confidently in a secure, scalable, and performance-tuned environment.
Ready to deploy your next AI project? Let’s talk.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected


About Author

Small Language Models (SLMs) are quickly becoming the go-to choice for businesses seeking AI that’s cost-effective, secure, and easy to deploy. While large language models (LLMs) like GPT-4.1 make headlines, most organizations don’t need billions of parameters or hyperscale infrastructure. They need practical AI.
SLMs deliver just that: performing targeted tasks with lightweight infrastructure and total data privacy.
So, what does SLM mean, and how can your business use them?
What Does SLM Mean?
SLM stands for Small Language Model, a lightweight AI system designed for specific tasks with fewer parameters than its larger LLM counterparts. Parameters are simply variables in an AI model whose values are adjusted during training to establish how input data gets transformed into the desired output. SLMs typically range from a few hundred million to a few billion parameters.
That’s significantly smaller than today’s top-tier models’ 70+ billion parameter giants. But don’t let the size fool you. These models are fast, highly specialized, and capable of running on personal devices, edge servers, or right-sized private cloud environments.
In fact, open-source SLMs like Phi-3, Mistral, and LLaMA 3 8B can be fine-tuned for your exact use case. No hyperscaler GPU cluster required.
And the momentum is only accelerating. According to Gartner’s April 2025 forecast, organizations will use small, task-specific models three times more than general-purpose LLMs by 2027.
Looking to migrate without overlap costs?
Migration shouldn’t drain your budget. With HorizonIQ’s 2 Months Free, you can move workloads, skip the overlap bills, and gain extra time to switch providers without double paying.Get 2 Months Free
SLMs vs LLMs: What’s the Difference?
While both use similar transformer-based architectures, their purpose, cost, and performance profiles are quite different. Choosing the right model depends on your business needs, not just model size.
Here’s a quick comparison:
| Feature | Large Language Models (LLMs) | Small Language Models (SLMs) |
Typical Model Size |
10B+ parameters | <10B parameters |
Hardware Requirements |
High-end GPUs or TPUs | Run on local devices or modest cloud VMs |
Latency |
Often high due to cloud inference | Low (can run on edge or private servers) |
Data Privacy |
Data typically leaves the local network | Fully local or private cloud processing |
Use Case Fit |
General-purpose, multi-domain | Narrow, domain-specific tasks |
Cost to Run |
High (GPU, bandwidth, inference fees) | Low (CPU-friendly, open-source models) |
Deployment Flexibility |
Requires cloud/hyperscaler dependencies | Deployable on-prem, cloud, or hybrid |
For a deeper dive into the architectural and cost differences, check out this detailed breakdown on SLMs vs. LLMs.
What Do SLMs Mean for Your Business?
Whether you’re building an internal chatbot, adding AI to a SaaS product, or streamlining document processing, SLMs offer key advantages:
- Lower cost of deployment on CPUs or entry-level GPUs
- No vendor lock-in when run on your own infrastructure
- Faster response times when deployed locally
- Greater data privacy with on-device or single-tenant hosting
These traits make SLMs ideal for industries like healthcare, finance, retail, education, and manufacturing—where security, compliance, and speed are critical.
What Are the Real-World Applications of SLMs?
The shift from general-purpose LLMs to task-specific SLMs is already transforming the way we use AI. This shift is helping businesses understand SLM’s meaning beyond the acronym, seeing how these models can bring real-time AI to classrooms, edge devices, and secure industries.
Education: Personalized Learning with Khanmigo
Khan Academy’s Khanmigo tutor is a standout example. Built with small language models, it gives students personalized feedback, encourages critical thinking, and adapts to individual learning styles, all while keeping data usage private and controlled by schools.
Software Development: Local AI Coding Assistants
Engineers and hobbyists are using lightweight open-source models like Phi-2 or LLaMA 3 Mini to run local AI agents for coding support, logic checking, and error debugging. Tools like LM Studio or platforms like Ollama enable on-device AI assistance with no cloud dependency.
Wearables and Edge Devices
Small models are even being integrated into smart glasses, phones, and vehicles. For example, Meta’s Ray-Ban smart glasses are beginning to use compact models for real-time translations and AI interactions, all processed at the edge.
Healthcare and Compliance-Heavy Industries
Doctors, financial analysts, and legal professionals are testing models that run directly on secure tablets or air-gapped servers. These setups enable SLMs to process sensitive data while keeping it fully contained within the organization’s environment.
To explore these use cases in depth, check out this excellent video by Ragnar Pichla, where he demos real-world SLM applications from offline AI assistants to on-device coding copilots.
Why HorizonIQ is the Right Home for Your Lightweight AI
At HorizonIQ, we can help you go from “What does SLM mean?” to full deployment—guiding you through model selection, infrastructure, and security best practices. Our private cloud offerings are purpose-built for:
- Single-tenant data isolation
- GPU or CPU-backed compute options
- Full control over model selection and environment configuration
- Flexible deployment across Proxmox or VMware infrastructure
You don’t need a hyperscaler to build lightweight AI. You need infrastructure that fits your vision and your budget.
SLM Meaning: The Future of AI is Smarter, Not Bigger
SLMs are not scaled-down versions of LLMs, they’re optimized for the real world. They give you the power of AI, without the sprawl of oversized infrastructure or the risk of data leakage.
From smart tutoring to offline language translation, the future of AI is already here. And it fits in your pocket.
Looking to build a secure, scalable AI stack around small language models? Explore how we support real-world AI with cost-effective infrastructure.
Explore HorizonIQ's
Managed Private Cloud
LEARN MORE
Stay Connected
About Author